Part 2: Kafka Fault Tolerance using Replica
If you replicate events on multiple Kafka servers, you still have all the data when one of the server crashes. The other server stores the data as well and is ready to deliver it to the consumers. This is the idea behind replica in Kafka. Note, however, that the overall platform is blocked if there is no Zookeeper up and running.
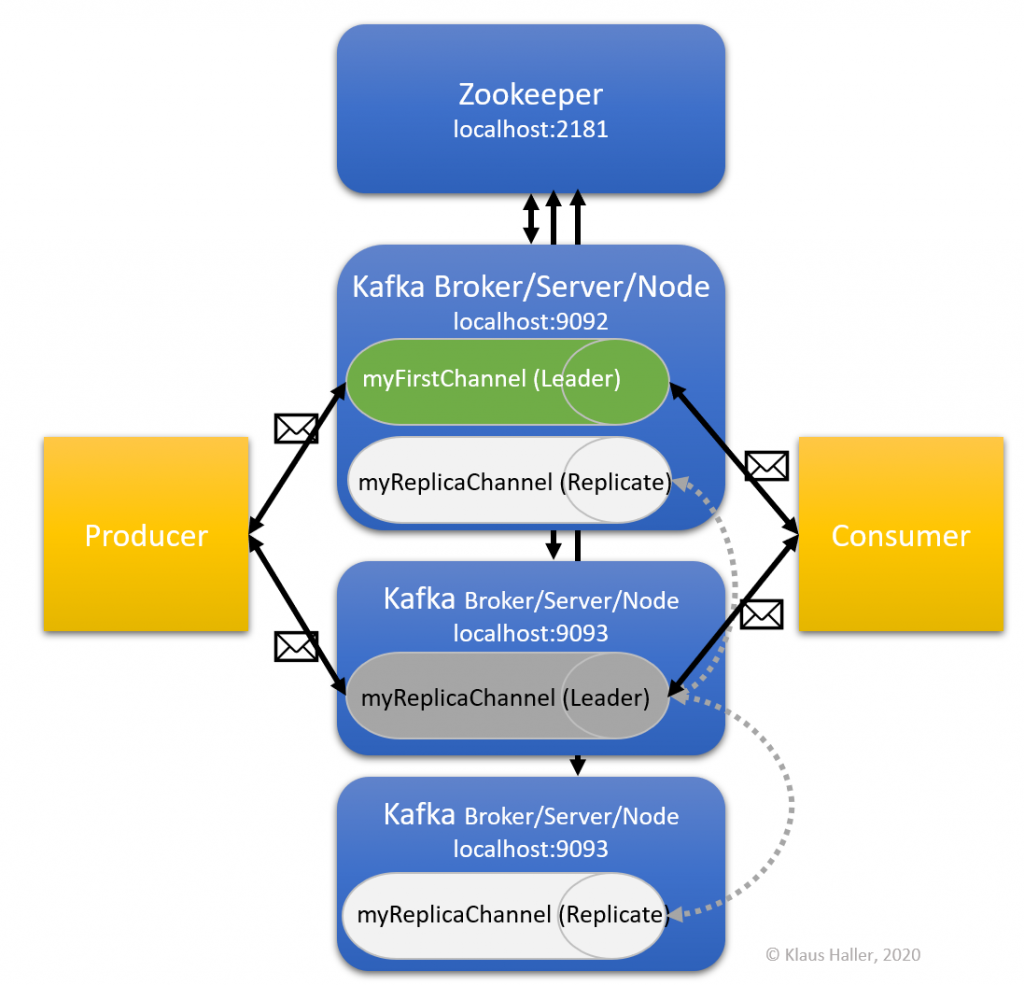
The concept is relatively simple for replica: There is one leader. It is the only one accepting new messages and events from producers and it is the only one delivering events and messages to consumers. Replica servers “just” get a copy of the events and messages from the leader.
To try out this functionality by ourselves, we extend our infrastructure by increasing the number of Kafka nodes from one to three and adding a new topic using the Kafka replica feature as shown in the figure below.
2.1 Configuring Additional Kafka Nodes
We copy the file server.properties twice to get two new files, server1.properties and server2.properties. In these files, we set the broker id parameter to 1 and 2. Also, we have to configure new log file directories for each of them, since we run all of them on our local machine in this tutorial.
So, the file server.properties should contain:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
[…]
# listeners=PLAINTEXT://:9092
[…]
# A comma separated list of directories under which to store log files
log.dirs=C:\Users\post\Kafka\kafka_2.13-2.4.0\logs_server0The file server1.properties should contain:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
[…]
listeners=PLAINTEXT://:9093
[…]
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners=PLAINTEXT://localhost:9093
[…]
# A comma separated list of directories under which to store log files
log.dirs=C:\Users\post\Kafka\kafka_2.13-2.4.0\logs_server1The file server2.properties should contain:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
[…]
listeners=PLAINTEXT://:9094
[…]
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners=PLAINTEXT://localhost:9094
[…]
# A comma separated list of directories under which to store log files
log.dirs=C:\Users\post\Kafka\kafka_2.13-2.4.0\logs_server2
2.2 Start the Additional Kafka Nodes
The next steps are straight-forward:
- Open a new command shell.
- Start a Kafka server using configuration file server1.properties (see Part 1 of the tutorial if you cannot remember the command).
- If everything went well, you should see the following:
INFO [KafkaServer id=1] started (kafka.server.KafkaServer) - Open another new command shell.
- Start a Kafka server using configuration file server2.properties (see Part 1 of the tutorial if you cannot remember the command).
- If everything went well, you should see the following:
INFO [KafkaServer id=2] started (kafka.server.KafkaServer)
At this moment, you should have four open command shell windows: one for the Zookeeper and three Kafka server nodes. All of them must be up and running to continue.
2.3 Create New Topic with Replication
Now the system is set-up so that we can create a new topic myReplicaChannel, this time using the replica features. We want to have one leader and two replica. We open another new command shell and execute the following command:
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic myReplicaChannel
Do you remember in which folder you have to execute this command?
Now, we create a new producer and consumer in two separate, new command shell windows using these two commands:
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic myReplicaChannel
and
kafka-console-producer.bat --broker-list localhost:9092 --topic myReplicaChannel
In the producer command shell, we type in “Replication is great!” and press the return key. Directly afterwards, we see this sentence in the consumer command shell window. So, what does this mean?
The implication is simple: There is no change for users respectively producers and consumers if we use the replica feature.
2.4 Checking the Kafka System State
Using the command line interface, we get an overview of the overall system state (in a later part of the tutorial, we look on more production-like monitoring solutions). More precise, we can use the Kafka topics command with the list option:
kafka-topics.bat --list --zookeeper localhost:2181
As a result, we get a list with our two topics: myFirstChanneland myReplicaChannel.
Let’s assume we do not only have one or two topics and “just” three Kafka nodes, but 50 topics and 15 nodes. We might be interested in understanding which server is involved in which topic – and how the actual configuration looks like. Did we specify 3 replica, or did we not consider this because we were experimenting with this topic for a while and forgot about this issue?
Here, we can use the topics command, this time with the “describe” option:
kafka-topics.bat --describe --zookeeper localhost:2181 --topic myReplicaChannel
Before continue reading, you might want to compare the result for the myReplicaChannel with the one for the myFirstChannel. When we submit the command above, we get this result:
Topic: myReplicaChannel PartitionCount: 1 ReplicationFactor: 3 Configs:
Topic: myReplicaChannel Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
So, what does this mean?
- All information regarding partitions is out of our focus now. We discuss in the next part of this tutorial.
- The replication factor is three with the Kafka nodes with the broker ids 0, 2, 1.
- The leader, i.e., the node all the producers and consumers communicate with, is the node with broker id 0.
- All replica are up to date, because they are all listed after “Isr”.
2.5 A Simple Failover Test
Now we want to check what is happening if we lose the leader node. Therefore, we terminate the process by closing the command shell. With our data above, the node with broker id 0 has to be terminated, i.e., the server started with the server.properties configuration. If we run the description command again, we will see that now a different broker became the leader. We will have a closer look on this topic later. First, we look on how Kafka enables parallel processing and, thus, a high throughput.
Before continuing to the next section of the tutorial, you can
Click here to go to the next part of this tutorial.