Part 3: Kafka Throughput Optimization using Partitions and Consumer Groups
Kafka is known for being able to process a heavy workload of messages and events. One way is to distribute the topics over various Kafka nodes. If you have 70 topics and 10 Kafka nodes, each node might be the leader for seven topics. Thus, Kafka can parallelize handling various topics while running a single Kafka cluster. In this section of the tutorial, we look on how to optimize the processing of the events of a single cluster using partitions and consumer groups.
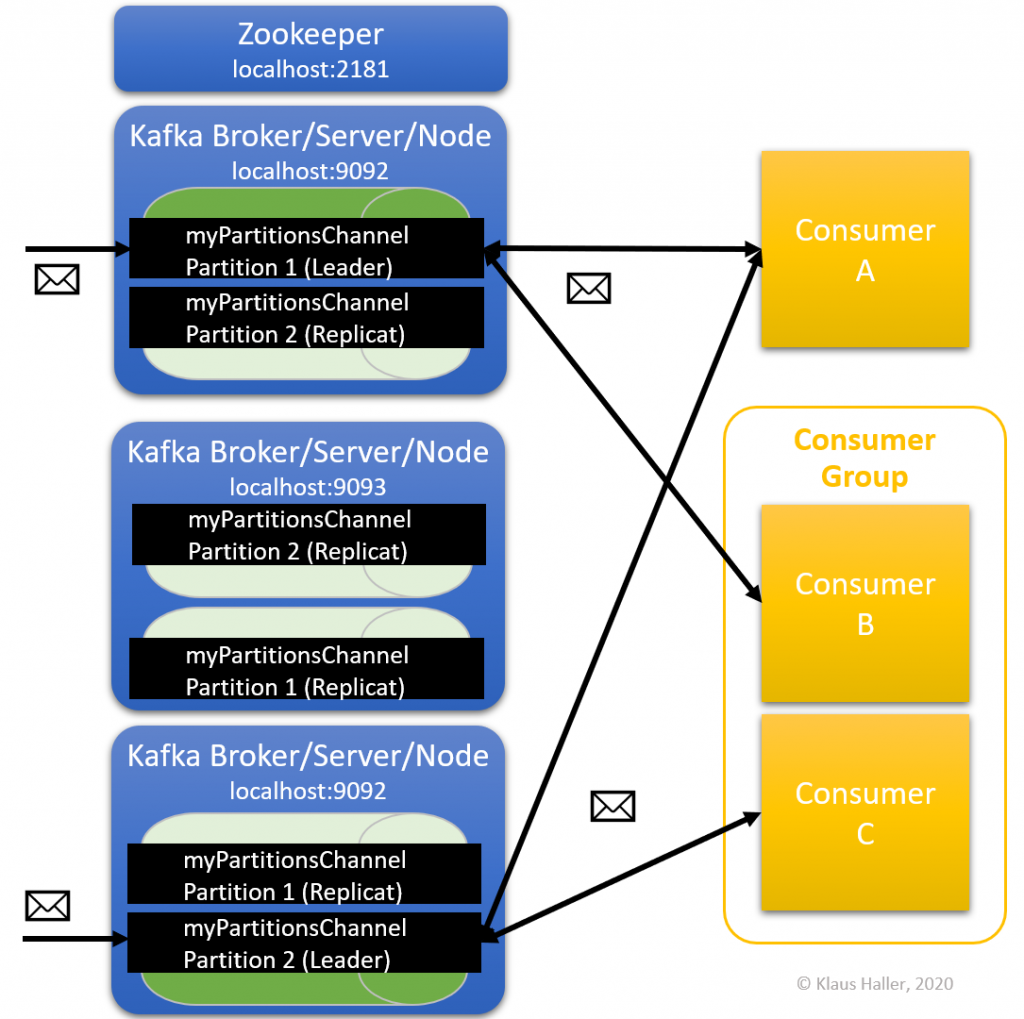
3.1 Kafka Partitions
Beside distributing topics over various Kafka nodes, Kafka can optimize the throughput also by distributing the workload of single topics over various Kafka nodes. This concept is called Kafka partitions. Each partition is a kind of event queue into which producers can write events and from which consumers can fetch events. Thus, events of a single topic can be handled, e.g., by 10 or 50 Kafka nodes. However, there is one aspect to be consider. All events of a partition are ordered, but there is no order between events of different partitions.
The number of partitions is defined on a per-topic level by setting the parameter during the topic creation. Before submitting the command, you might want to check whether your Zookeeper process and the three Kafka nodes/brokers are still running.
The command for the topic creation is the following:
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic myPartitionsChannel
Now let’s have a look how our platform looks like using the topics describe command:
kafka-topics.bat --describe --zookeeper localhost:2181 --topic myPartitionsChannel
The result should look similar to that that:
Topic: myPartitionsChannel PartitionCount: 2 ReplicationFactor: 3 Configs:
Topic: myPartitionsChannel Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: myPartitionsChannel Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
We see that the Kafka broker, that is the leader, differs for partition 0 and 1, allowing for workload distribution if the brokers run on different virtual machines.
In a new command shell, we start a consumer listening at partition 0 for the new topic:
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic myPartitionsChannel --partition 0 --from-beginning
In another new command shell, we start a consumer listening at partition 1:
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic myPartitionsChannel --partition 1 --from-beginning
Finally, we start – in yet another command shell – a new producer:
kafka-console-producer.bat --broker-list localhost:9092 --topic myPartitionsChannel
If we type in “Hello1!” and press the return key, the message is displayed by only one of the consumers. What happens if you send more messages such as “Hello2!”, “Hello3!” etc.?
3.2 Consumer Groups
Another concept, closely related to partitions, are consumer groups. They are an efficient way to distribute the work processing the events delivered by the Kafka infrastructure. Assume an image processing system. An “analyze image” service might need 2 seconds per image. If there are around 1000 images per second coming from Kafka, one process cannot handle all the load. Here, the concept of Kafka Consumer Groups helps.
Up to now, the rule was that each consumer reads all messages of the topic the consumer subscribed to. If there are two consumers, each consumer reads all message. Each message is read twice. If two brokers form a consumer group, this is different. A message is read only by one consumer of the group. This is perfect for the image processing example. You start 500 image processing processes, each one is Kafka consumer, and all together they form one consumer group. So, every time one of the image processing processes finishes the processing of one image, it contacts the Kafka broker and fetches the next image.
There is just one aspect to be considered: Each consumer of a consumer group can connect to one or more partitions. However, each partition delivers only events to one consumer of a consumer group. Thus, it does not make sense to have more consumers in a consumer group than there are partitions.
3.3 Summary: Partitions, Consumption Groups, and Replica in Kafka
To prevent any confusion, I want to point out the differences between partitions and replica:
- Replica help if a Kafka broker crashes. They ensure that no data is lost. Also, one of the replica nodes can take over the role as the leader interacting with consumers and producers of topics. Thus, such crashes do not impact consumers and providers at all.
- Partitions are measures for throughput of the Kafka platform. You distribute the events of a topic over various Kafka so that there is less load on a single machine. This helps if there are too many events to be handled by a single Kafka node.
- Consumption groups help when processes and applications outside of Kafka struggle to process all the events coming from the Kafka platform. Consumption groups ease distributing and parallelizing such work.
In the next part of the tutorial (to be released in Februar 2020), we look at security configurations.