
Backup features are core services all public clouds provide. Azure’s characteristic is a confusing backup service portfolio. Two backup technologies coexist: Azure Backup vault and Azure Site Recovery vault. None is better—the data source you want to back up defines which vault type to use – and there are services that even backups in different ways. As a rule of thumb, the Service Recovery Vault is the solution for typical IaaS workloads such as Windows and Linux VMs, Fileshapres, and specific databases running on VMs. Azure Backup Vault is strong with Azure PaaS services. Azure starts to hide the complexity by introducing the Azure Backup Center (Figure 1). It is a unified user interface for handling backups in the Azure portal. Still, when architecting the backup solution, understanding the differences is crucial. Even for one vault type, nuances depend on the data.

A typical enterprise workload in Azure cloud might comprise of …
- VMs and their disks
- Object Storage, i.e., Azure Blobs in Azure Storage Accounts
- File Storage in Azure Storage Accounts
- DBaaS (Cosmos DB, Azure SQL Managed Instance, Azure SQL)
Then, a service recovery vault would take the VM, including customer-installed and managed databases installed on VMs, plus file systems stored in Azure’s Storage Accounts. Blobs and DBaaS data, however, go into a Backup vault, though things turn out to be different than expected if you take a closer look as we do in the following paragraphs. We discuss how to configure ad-hoc and periodic backups for blobs and DBaaS. And the interesting aspect is: In the most recent forms, the Backup Vaults are not or only slightly involved.
Operational Backups for Azure Blobs
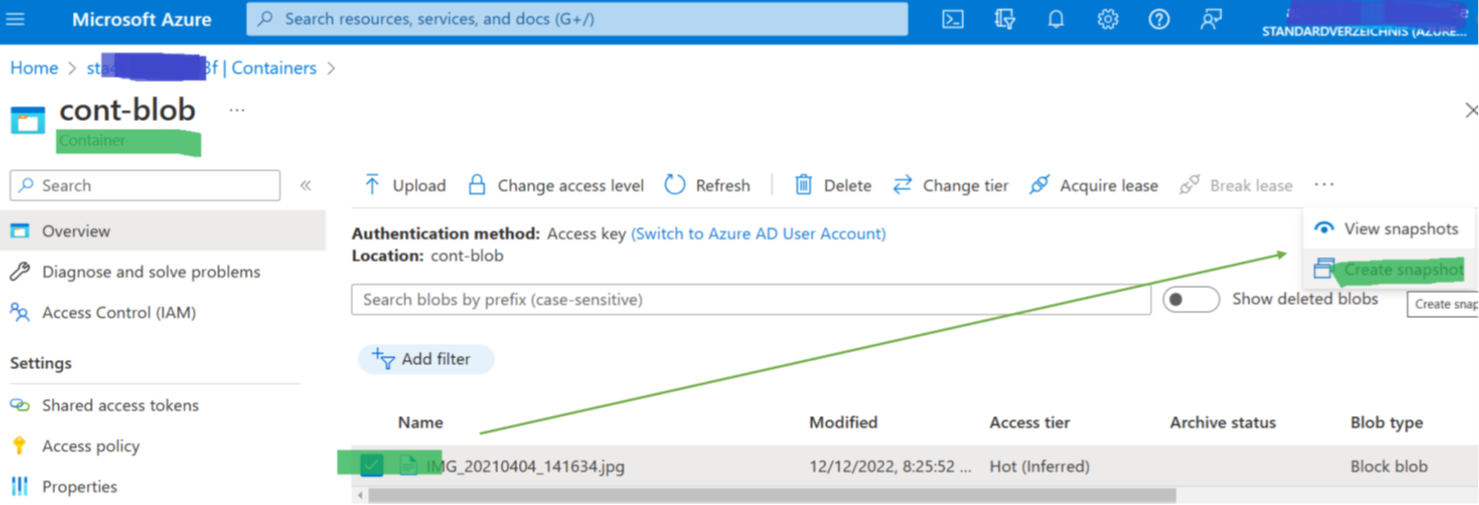
The quickest way to back up a single Blob in Azure is to go to the Azure portal, switch to the blob, and select “make a snapshot” – and you are done (Figure 2). Super convenient and super quick, just not doable if you have hundreds of storage accounts and want to be sure that you get a backup every hour.
For backup automation, Azure’s most advanced solution for blobs in Azure Storage Accounts is the Operational Backup for Azure Blobs feature. Azure Storage Accounts can have multiple (block blob) containers (Storage Accounts can also store and manage other data: file shares, queues, or tables). The actual blobs reside inside these containers. Figure 3 illustrates these three main blob management layers and how they contribute to securing blob backups.

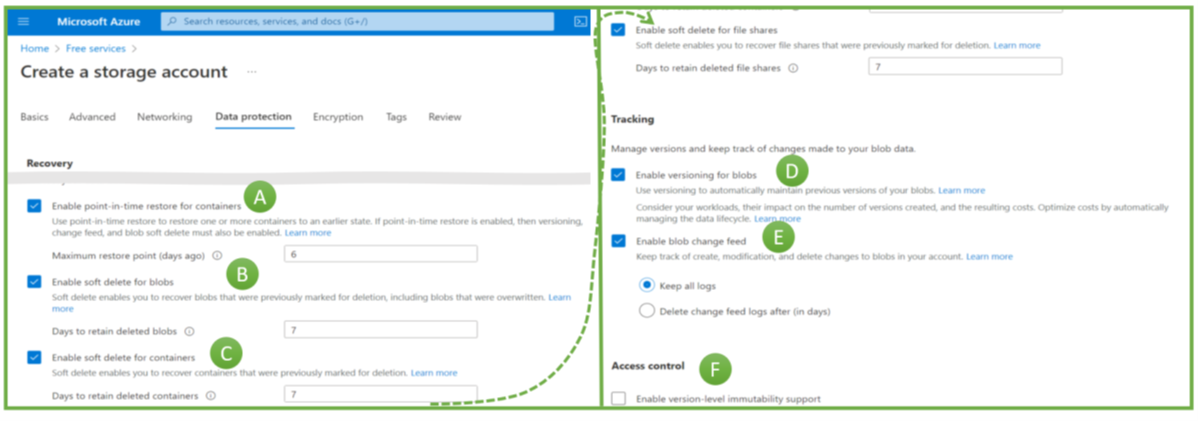
When creating a storage account in the Azure portal, engineers make several backup-related choices, as the options in Figure 2 illustrate:
- Point-in-time recovery (PITR): The ability to roll back to anytime within the retention period. The maximum value is 360 days (Figure 2, A).
- Soft-delete for blobs and containers (B and C). If these features are active, Azure keeps a copy of blobs and containers after their deletion. Engineers could restore them if the deletion was a mistake (or a malicious activity). Soft-delete for blobs allows restoring a single object, but soft-delete on the container level is necessary when someone deletes a container with the included blobs.
- Versioning for blobs (D): In contrast to files, object storage does not modify a blob. It replaces a blob with a newer version. Versioning means keeping (some) older versions. Azure can restore an older blob version, e.g., if modifications were incorrect or if ransomware attackers replace objects with encrypted versions.
- The version change feed (E) is Azure’s feature to ensure non-repudiation of blob changes by logging any change.
- The immutability feature, if switched on, makes it impossible to delete a backup for a defined period. No administrator, hacker, or Microsoft employee can delete backups protected with this feature.
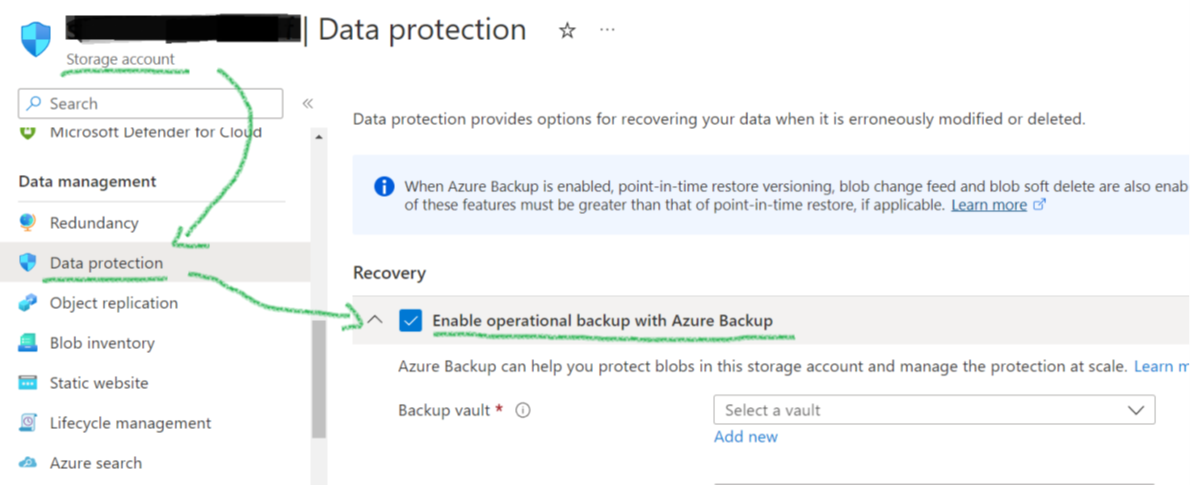
After creating the Storage Account, engineers can lock in the immutability setting and switch on the already mentioned “operational backup” feature. It comes with many features mentioned in the last paragraph: PITR, versioning, and soft-delete. Its biggest benefit is the integration with the general Backup Center management GUIs (Figure 5).
Protecting the Backups
Network-level shielding and access control, disaster readiness, backup loss prevention – these three topics drive the protection of your backups. Network shielding reflects the protection of the backups and the backup-related services on the network level. The actual backups are never directly accessible for Azure customers and users, only via the portal. Shielding the service for a concrete Azure tenant is possible with private endpoints. They are the method of choice in the Azure (PaaS) world, complemented by role-based access control based on identities and roles managed in a central solution, e.g., the Azure Active Directory. Privileged Identity Management (PIM) is Azure’s feature for even more security for privileged roles and users, valuable not only for classic admins but also for engineers who configure backup settings.
The second big topic, disaster readiness, relates to preparations for surviving large-scale incidents. A backup does not help if located in the same burned-down data center as the VMs. Thus, geo- (or zone-) redundant backups are valuable. Finally, backup loss prevention is about preventing backups from being deleted by successful attackers – or due to operational mistakes of employees. Two features drive this aspect:
- Resource Guard to enforce a four-eyes principle before critical backup-related operations
- Immutability, i.e., the absolute impossibility that anyone can delete a backup.
Finally, if you encrypt the backup with a customer-managed key, restoring the backup is only possible if the specific keys exists – but encryption and key management are big topics. One article is not enough to cover all the relevant aspects.
Backups for Azure Database for PostgreSQL
PostgreSQL is one of the database-as-a-service offerings from Microsoft. And when looking just at the various PostgreSQL variances, the full complexity of backups in the cloud using Azure-native tools becomes visible. The PostgreSQL variants are single server, flexible server, and Azure Arc. The latter addresses mixed on-prem and cloud workloads, so I focus on the first two. A first glance at the backup features tells you that backup vaults are where the backups are stored – and that immutable backup is an available feature (at least in the preview). But this holds only for the PostgreSQL single-server variant. The flexible server variant is the one you probably choose for newer software architectures. What Azure-native backups offer here differs, as I lay out in the following paragraphs.
Initially, a short remark on how PostgreSQL works internally for storing and managing the data: An Azure PostgreSQL flexible server instance is what one calls a database server in the on-prem world. It is an environment that can host many databases with the actual data. So, we have a three-layered model – flexible server, database – data. Regarding backups, there are many similarities with blob backups but some distinct differences. Most importantly, point-in-time recovery is available with a maximum retention period of 35 days. Azure allows configuring these backups as geo-redundant, in which context Microsoft mentions a recovery-point objective of around 1 hour, though this is not a guaranteed service level agreement. However, there is no built-in solution for long-time backups. Customers have to implement their backup solution with the help of the PostgreSQL command pg_dump. They must implement processes performing daily exports and cleaning up older backup files.
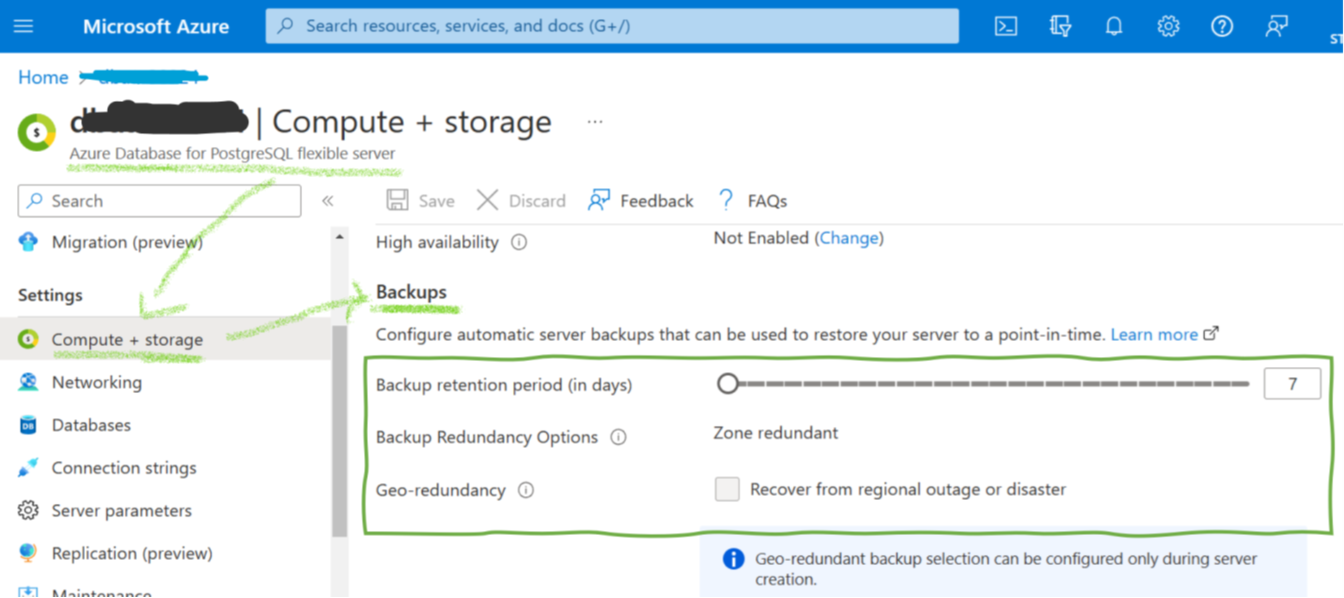
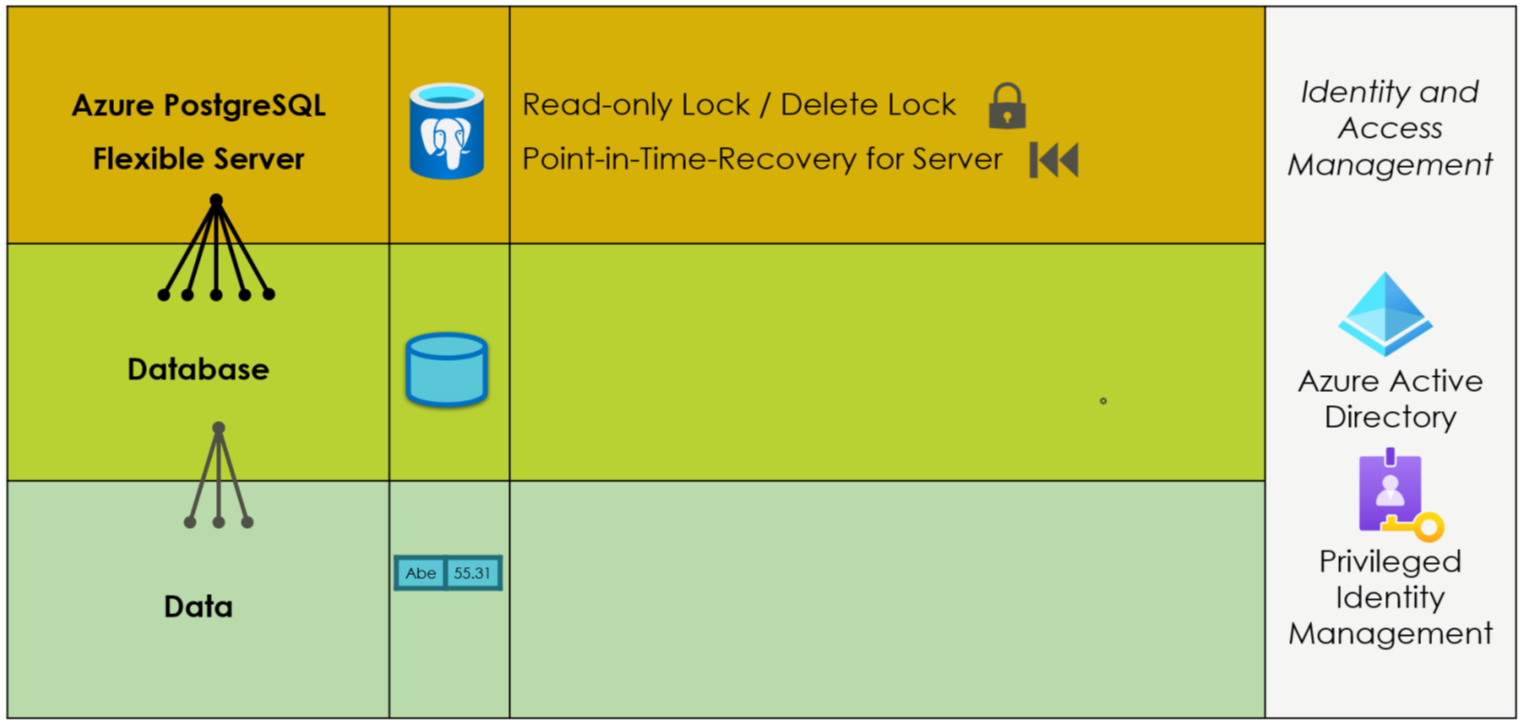
Securing PostgreSQL Flexible Server Backups
The security features for PostgreSQL flexible server backups are much more limited than for blobs, as Figure 3 illustrates. Identity and access management restrict access for users, at least if attackers cannot hack a company’s Active Directory. The continuous backup for point-in-time recovery provides the option to roll back the database server for a defined number of days. The only built-in security feature, however, is a delete lock preventing the deletion of the flexible server. The deletion of the server automatically deletes all backups. Adding and removing a lock on the server is an action users with a specific role can add and remove. If an internal user with such a role (or an attacker who could overtake a user with such a role) deletes the lock, he can delete the complete server with all its backups afterward. There is no built-in immutable backup option, though writing backup routines to dump exports to immutable (blob) storage is an option. Otherwise, IT departments really have to trust their Active Directory security measures and their admin and backup employees if they rely on such backups.
So, what is the conclusion for cloud security architects from what we can learn from Azure cloud-native features for backups for blobs and PostgreSQL flexible servers? First, many advanced cloud-native backup features help companies to improve their backup implementation. Second, the availability of features depends on the exact PaaS service and service variant. In other words: it looks chaotic and random, which backup features an Azure (database or storage) service has. Thus, the third and most important learning is: ensuring a defined backup service level for a complete application landscape in Azure is a big challenge for architects. It requires governance, which cloud services applications can use, and clear, enforceable guidelines on performing and securing these backups.