VMs and Fileshares are fundamental building blocks for IaaS workloads in on-prem or cloud environments such as Azure. So, which features does Azure provide for companies to back up their IaaS-related data and components? And how does Azure help prevent undesired manipulations or deletions of such backups? To answer these questions, this article elaborates on the interplay between, first, Azure’s VM and file share services and their configurations with, second, Azure Recovery Services vaults for providing, managing, and maintaining VM and file share backups.
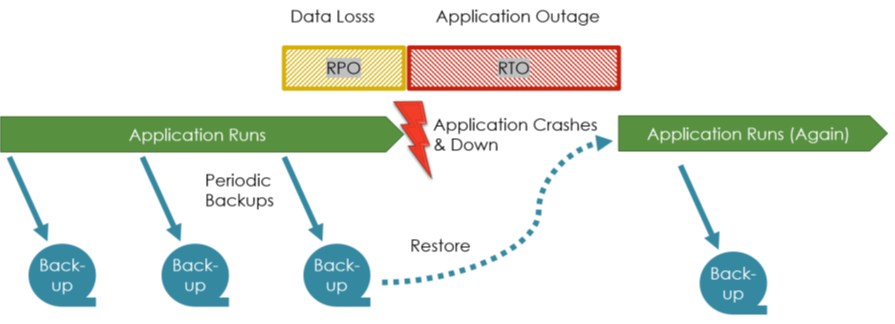
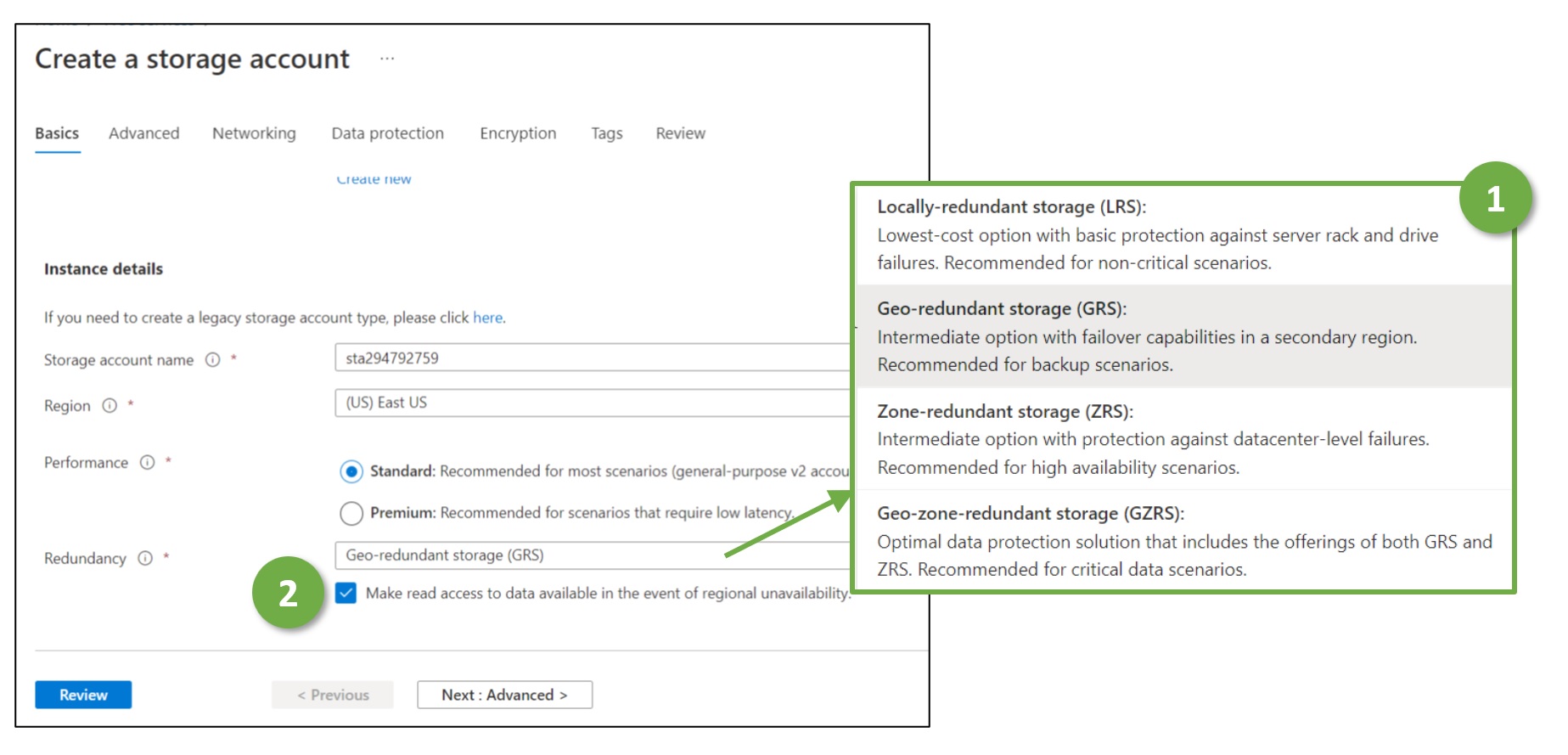
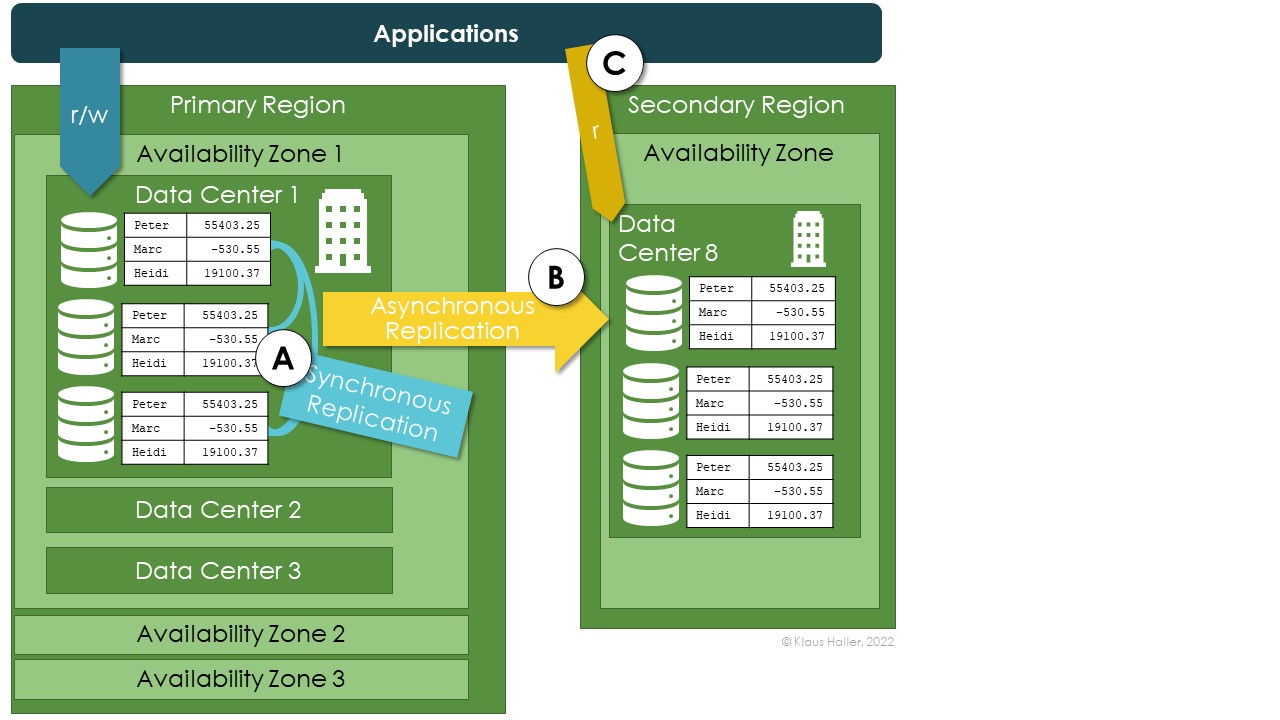
An initial remark before going into details. Geo- and zone-redundancy are related but different concepts. They reduce the risk of data loss due to the unavailability or destruction of hardware components and data center incidents. They do not allow restoring earlier versions of the data and backups in case of data mismanipulation. “Going back in time” is the unique selling proposition of backups. Though, keeping backups in various geographic locations helps, e.g., if a larger electricity blackout brings down data centers for days in a larger geographic area.
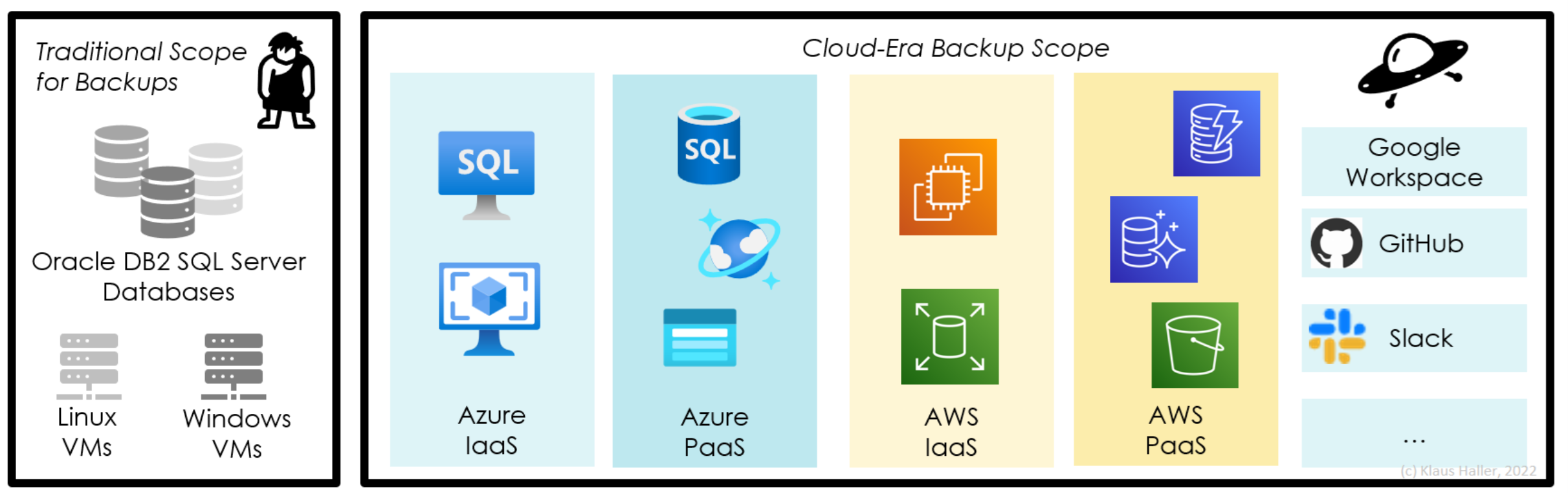
Backup Features for VMs in Azure
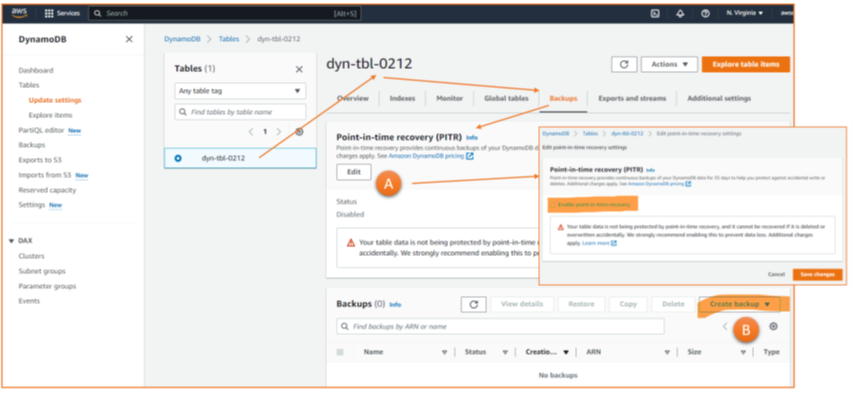
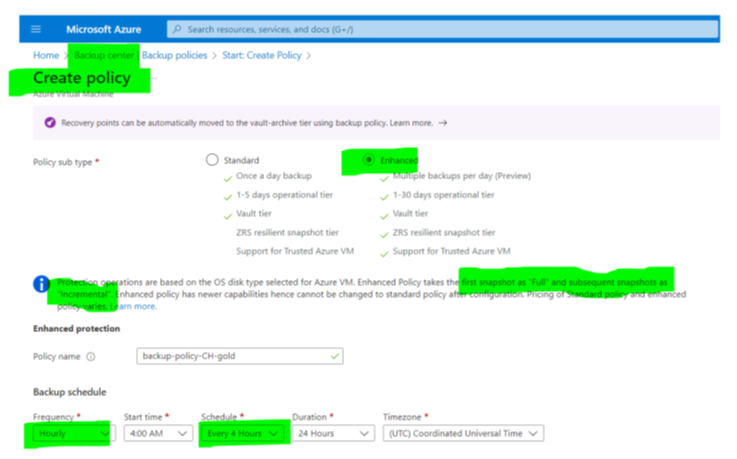
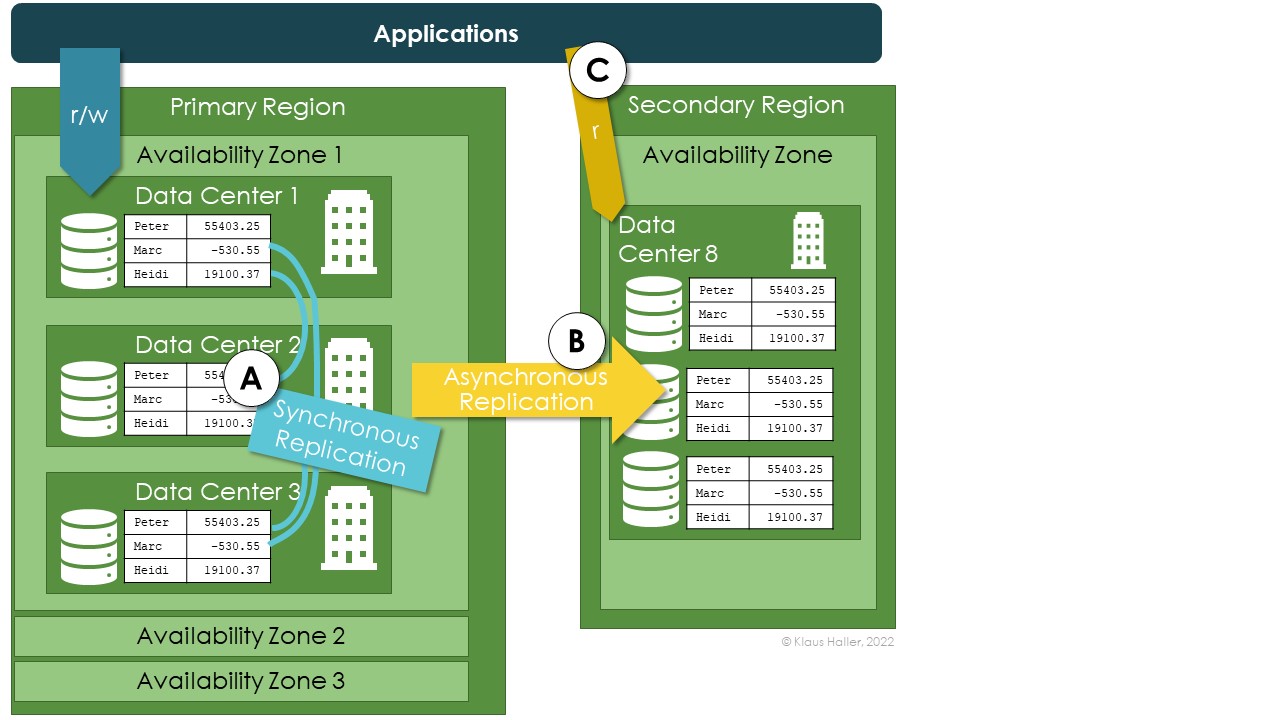
Azure’s solution for backups of IaaS cloud workloads is the Recovery Services vault (RSV). The configuration for VM backups in the portal is straightforward. With the “enhanced backup” feature, Azure can backup VMs up to every 4 hours (Figure 1, 1). There is an option to keep backups close to allow for a quick restore (2). Most important, and not available for all types of data and services in the cloud, Azure provides a long-time storage option to keep one backup per week, month, or year for months or even years (3). The final configuration option in the Azure portal is the list of VMs in scope for the backup – then, the configuration is complete.
Protecting and Securing VM Backups in Azure
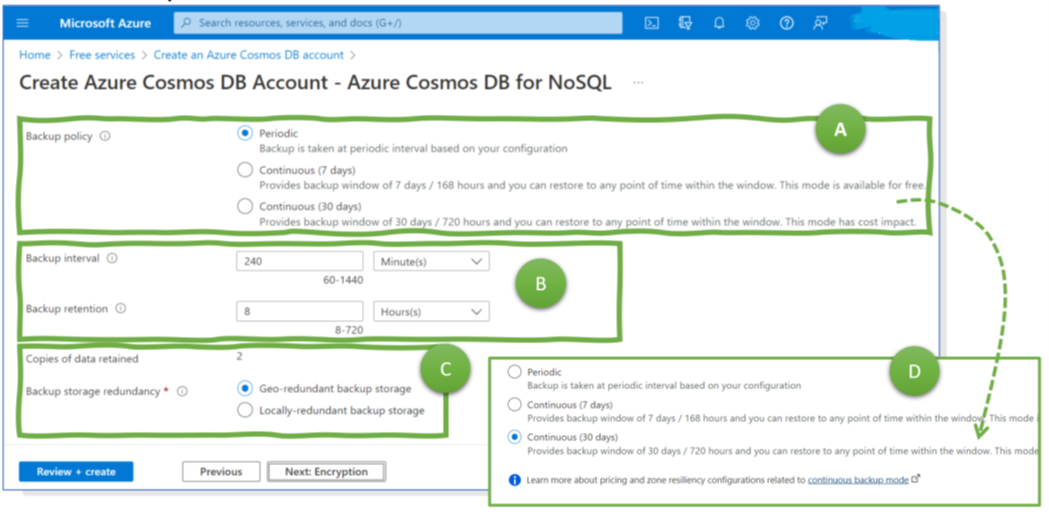
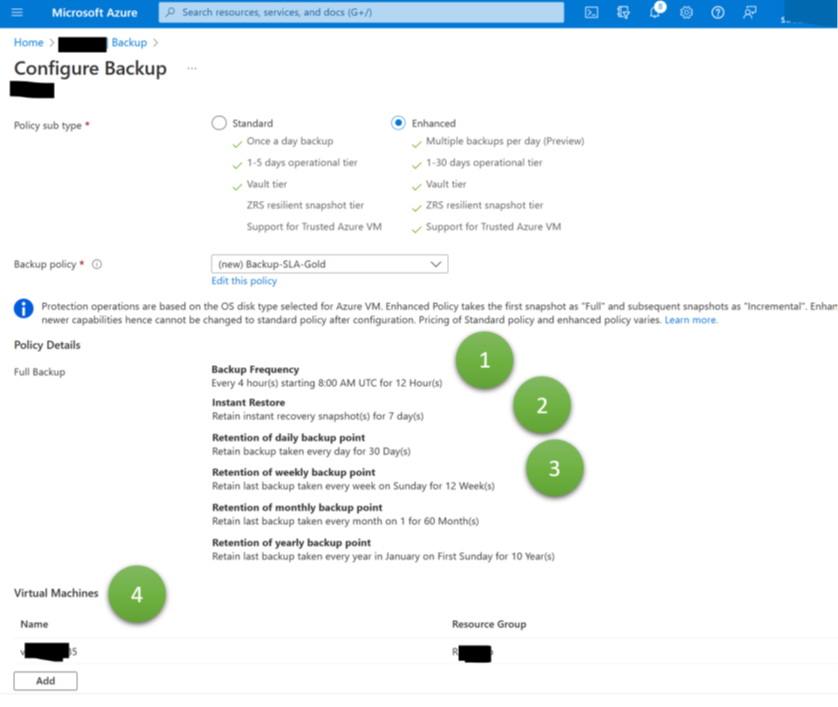
Azure has various built-in features for preventing accidental or intentional deletion of backups. The most radical is the “immutable” option (Figure 2, 1). If switched on (and locked in), backups cannot be deleted before the retention period expired. This immutability feature is a lifesaver if ransomware attackers delete or encrypt critical data. A second feature, multi-user authentication (2), enables IT organizations to demand that a second person approves critical activities such as vault deletion operations or modifications of backup policies. It benefits organizations by preventing severe misconfigurations resulting in the loss or unavailability of current or future backups, whether by mistake or on purpose. To formulate it differently: Immutable backups help rebuild your data center after really severe incidents. Multi-user authentication helps prevent such a mess from happening in the first place and ensures that your backups exist.
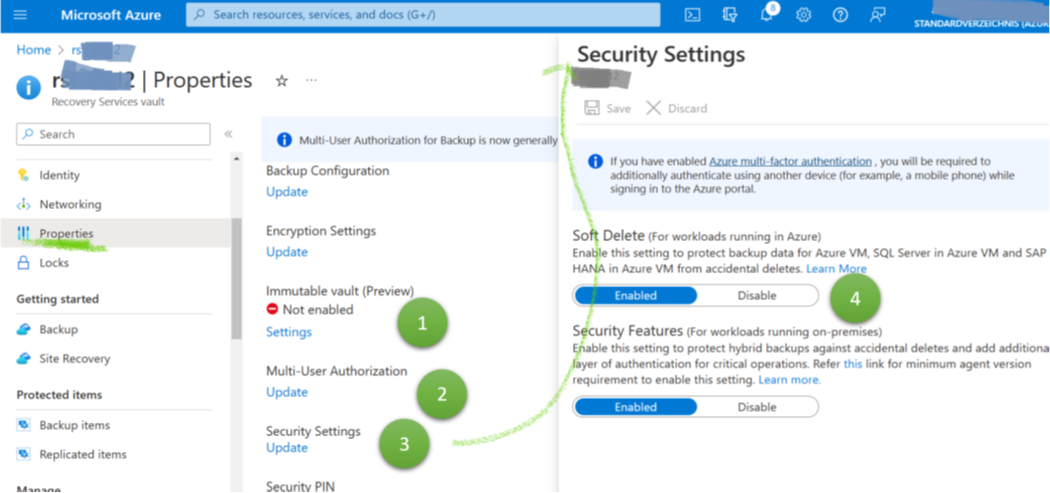
Finally, the soft delete setting allows enabling the feature to roll back deletion operations (Figure 2, 3 and 4). In the context of VM backups in RSVs, the feature is especially beneficial to restore the status quo ante after smaller application management or engineering mistakes. If application managers notice something was deleted by mistake some time ago, they can easily restore it. Helpful for operational mistakes but only of limited value for ransomware attacks. Engineers can circumvent the soft delete feature – and even Microsoft documents how to delete all data forever, even if soft delete is active. A closing remark for VM backups: These configuration options apply to VMs and their backups though configurations take place via Recovery Services vaults.
Azure Fileshare Backups
File shares are not a CISO’s darling, but the technology exists for decades and probably continues to live for some more years. File shares enable uncomplicated interactions between users themselves, applications themselves, and between users and applications. It might be an often-redundant technology, but the ability to use file shares is a must in any context of legacy applications.
Fileshare Backups in Azure
While (in the portal) the relevant configuration options for Azure VMs backups are on the Recovery Service Vault, the situation is different for file shares. Many backup-related configurations take place on the Azure Storage Accounts, which contain the file shares. And a warning for those who understand backing up Azure Blobs, which are also stored in Azure Storage Accounts: backups for blobs (see “Blob and PostgreSQL Backups in Azure”) differ from the ones for file shares.
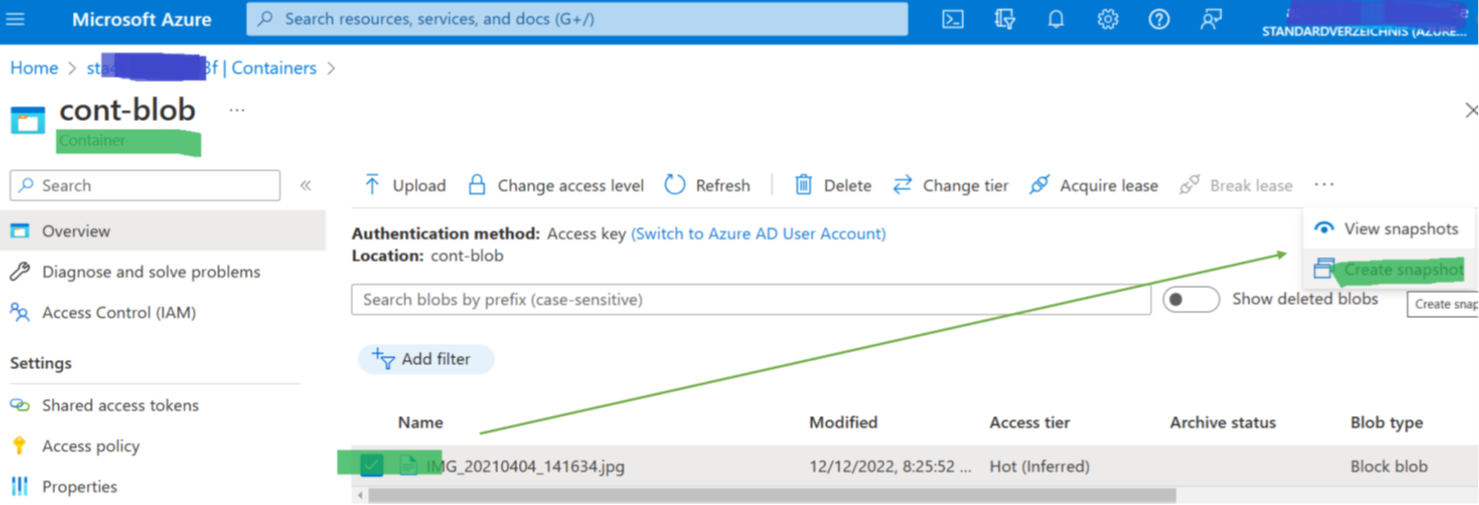
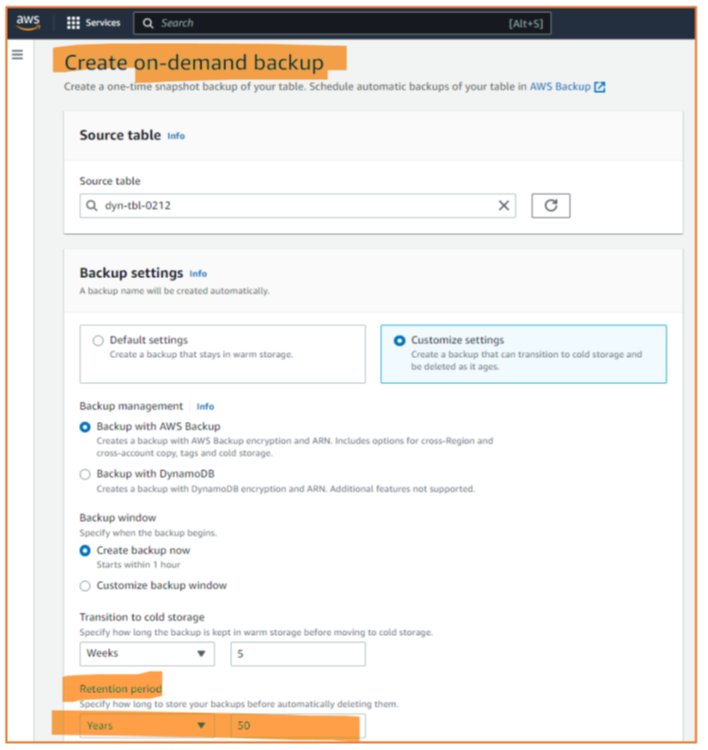
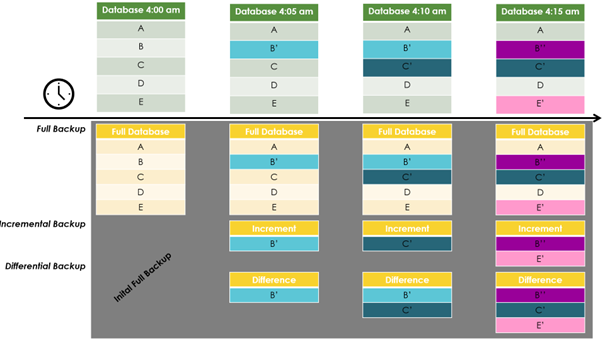
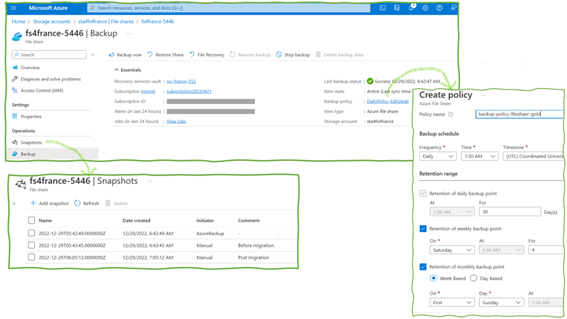
Azure supports ad-hoc backups (just click “add snapshot” in the portal’s snapshots mask) and periodic backups (Figure 3). Configuration options for periodic backups are the frequency (every four hours or less often) and how long backups are kept. Azure allows configuring retention periods of several years.
Protecting and Securing Fileshare Backups in Azure
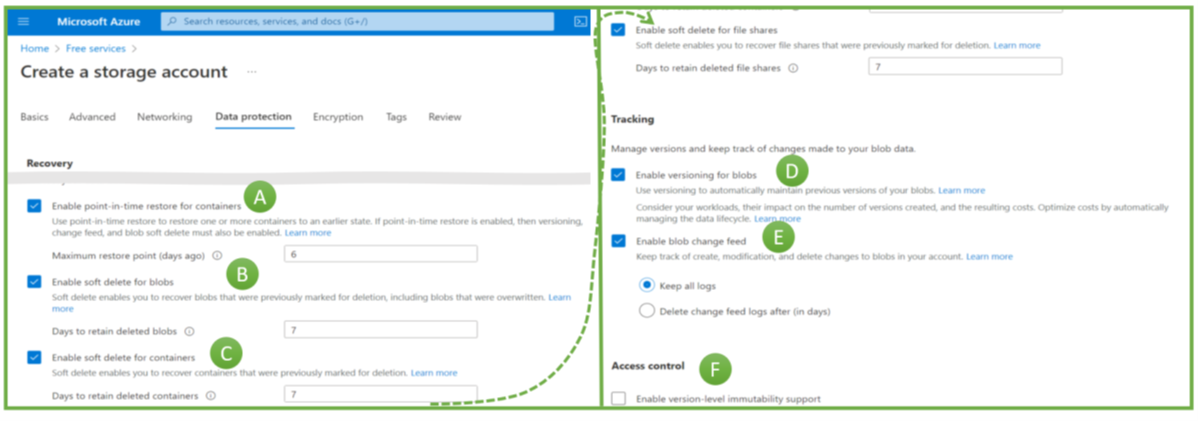
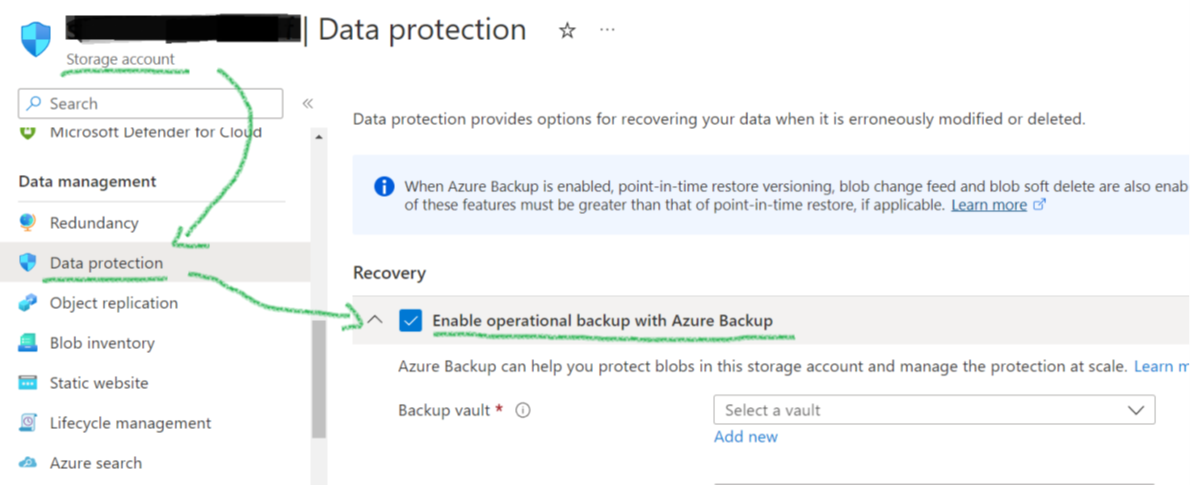
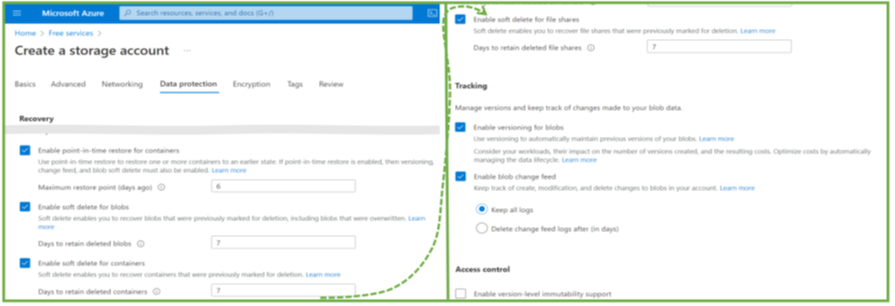
Protecting file share backups is delicate because it is not just about protecting the backups. It is also about protecting the Storage Accounts. They contain the actual backup data. If deleted, all associated backups are gone. Thus, cloud security architects should be aware of the various configuration options for Storage Accounts and Recovery Services vaults to prevent the deletion or discontinuation of critical backups (Figure 4).
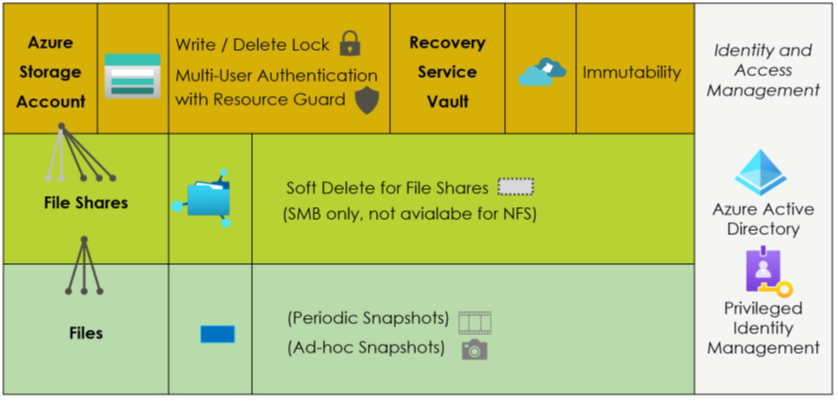
On the top are configuration options on the Storage Account level and for the Recovery Services vault. Most important is the immutability feature. When active and locked in, it guarantees that nobody – and really nobody – can delete these backups. It is a brand-new feature in public preview. Second, there is an option to forbid deleting the Storage Account utilizing a delete-lock. It makes deleting Storage Accounts hard to impossible. The different purposes are crucial: immutability is about having a backup when someone tries or succeeds in deleting all or critical data. The lock helps more to prevent the Storage Account deletion, which would bring down applications (even if the data can be restored with an immutable backup). Thus, its purpose is to improve reliability and application uptime.
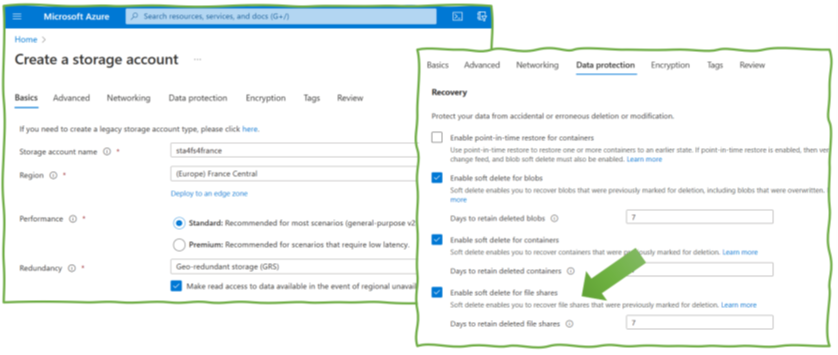
On the Azure File Share level, Azure provides the soft-delete feature (Figure 5). It has some peculiarities, especially since Azure supports soft-delete for SMB file shares and not for NFS ones. The SMB variant is particularly strong in the Windows respectively Microsoft world. The scope for soft-delete is not a single file but complete file shares. If switched on, engineers can restore a file share after its deletion. However, it does not bring back individual files if they are deleted. For this, the backup functionality with periodic backups or ad-hoc snapshots has to be used. So, to conclude: Azure provides various backup-related features, but understanding them in detail is critical to prevent issues if organizations really need them in critical situations.