
PaaS services promise software engineers nothing less than effortless eternal happiness: a few clicks and you have ready-to-use, secure, and unlimited scalable cloud service, be it an AI, a database, or a super-exotic service. But do cloud providers deliver as promised? Is, for example, redundancy a child’s play? Redundancy is much trickier than backups. Backups are about having a copy of an application’s data for emergencies. In contrast, redundancy guarantees that the application runs 7×24. Even major disasters must not impact a solution’s stability.
In the following, we look closely at one crucial Azure service, Azure Storage Accounts. It is Microsoft’s web service for storing data such as objects respectively, blobs, or files. We elaborate on which kind of disasters or failures the web service copes with – and how transparent it is from an application or operations perspective. Azure provides different options for configuring the recovery behavior of Storage Accounts (Figure 1), which the following paragraphs explain in more detail. Companies need specific guidelines on when to use which one – and writing such a guideline is a crucial cloud (security) architecture task.
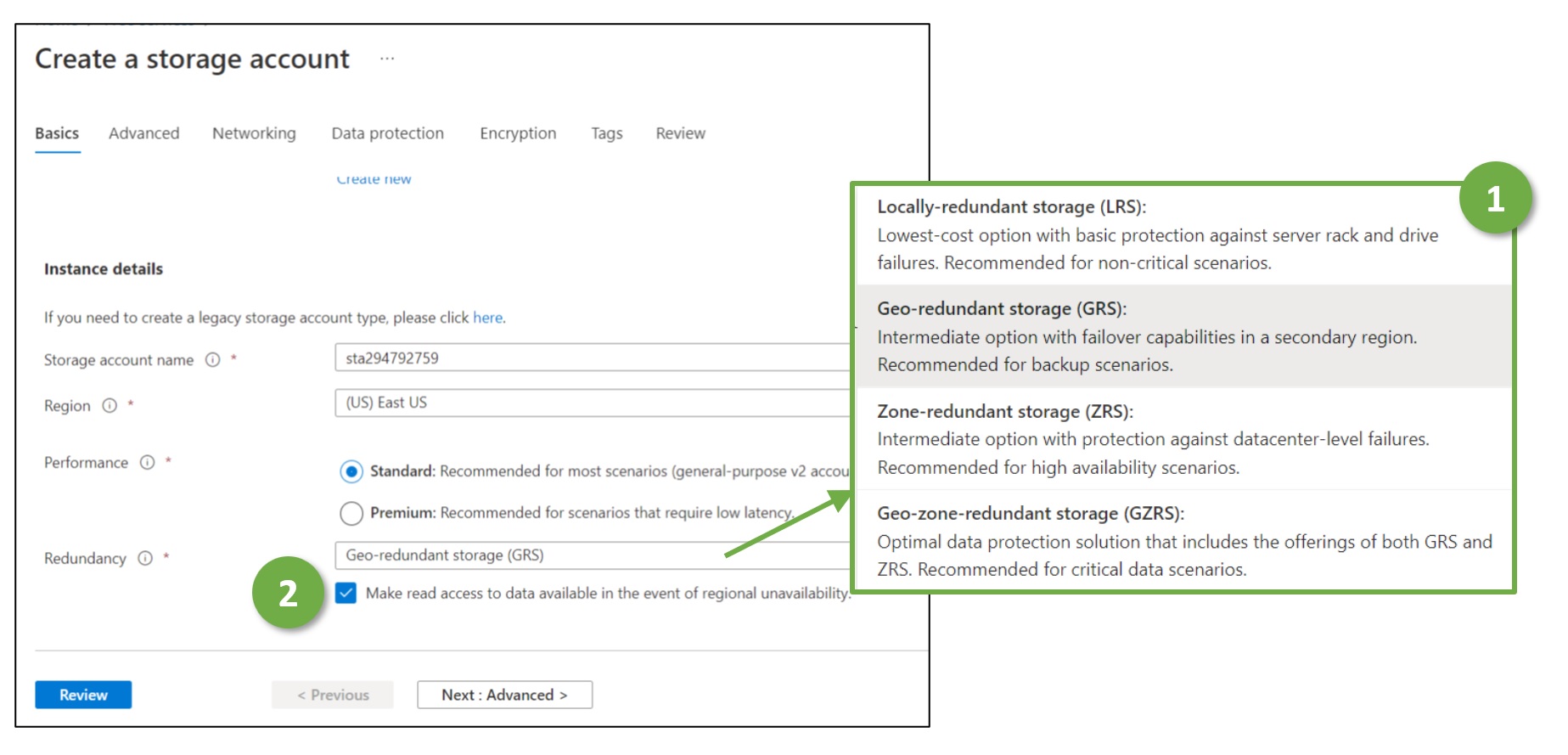
Cloud architects have to make (up to) three redundancy-related configuration decisions:
- Should the data be replicated three times within one data center (local redundancy), or should there be a copy in three separate data centers (zone redundancy)?
- Should there be copies in a data center further away in a secondary region (geo-redundancy)? For regulatory and compliance reasons, geo-redundant copies are usually in the same jurisdiction as the original data. Azure stores, e.g., geo-redundant copies for data in Switzerland-North (greater Zurich area) in the Azure region Switzerland-West around Geneva.
- Should applications be allowed to read the geo-redundant copies if the primary region fails (“read access”)?
Figure 2 and Figure 3 illustrate the configuration options for a better understanding. The architecture in Figure 2 visualizes local redundancy. An application reads and writes data stored in one data center (A). The different copies are synchronously replicated and always in sync. If – and only if – the engineers choose the geo-redundant add-on, Azure replicates the data asynchronously to one data center in a secondary region (B). In such a case, the Storage Account can be configured to allow applications to read from the storage account in the secondary region if the first region is unavailable (C).
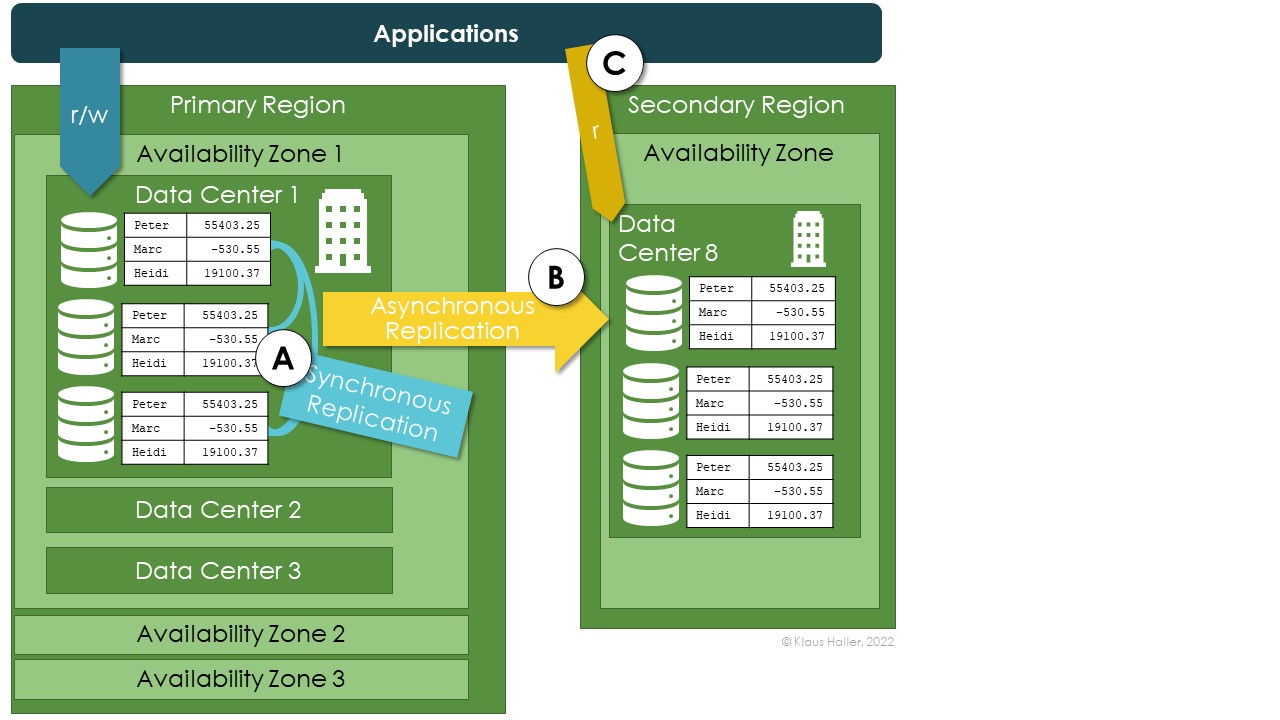
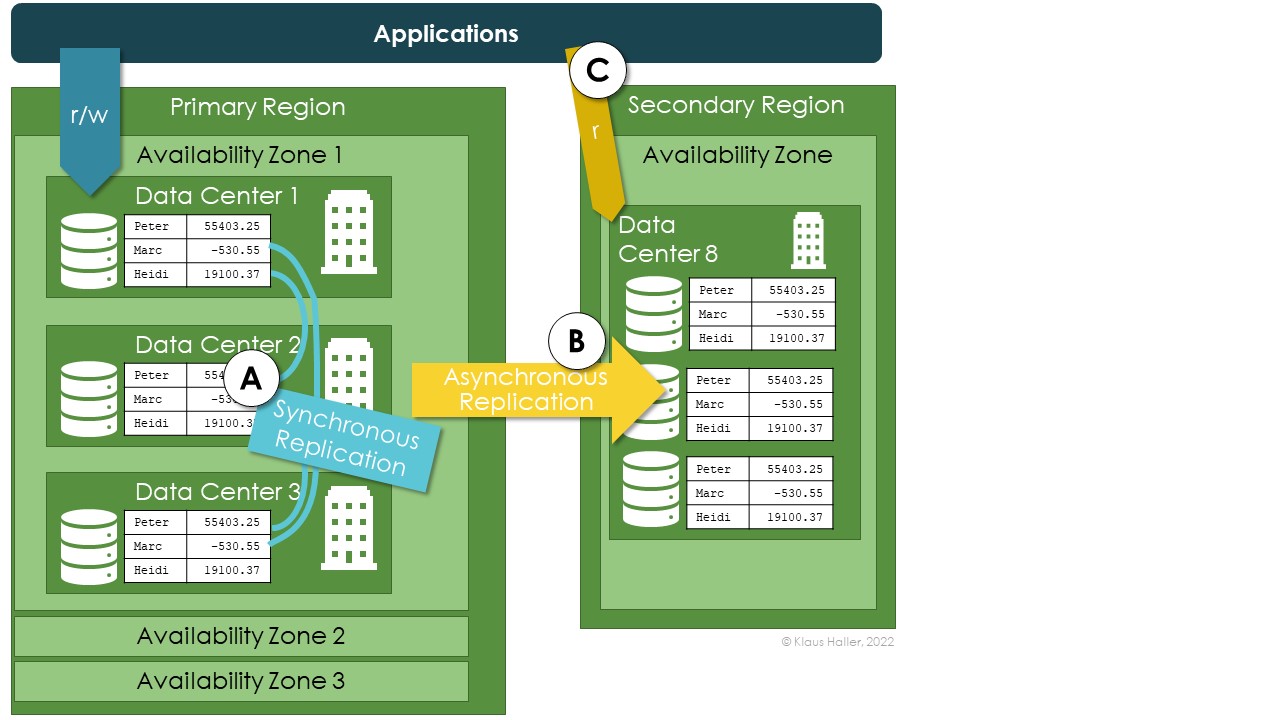
Figure 3 looks very similar. It illustrates zone-redundancy. In such a set-up, the three copies are in different data centers in the primary region (A). If geo-redundancy is active, all asynchronous copies in the secondary are stored in the same single data center (B)as in the previous case in Figure 2. Applications can get read access in case of unavailability of the primary region – as with local redundancy (C).
In the next step, we look closer at three failure scenarios: a failure of a single device, a data center, and an entire region. Which configuration option allows the application to continue to run? How transparent are such incidents for applications? What does the cloud operations team or the applications team have to do?
First, a failure of a single device in a data center has no impact on any application or operational staff. Azure always maintains three up-to-date copies of any data, be it in one or be it in three data centers. These copies are always in sync. Thus, if a device fails, another device in the same or another data center takes over and has precisely the same data. There is neither data loss nor interruption of application availability, nor any necessity for manual interventions.
A failure of a complete data center is transparent for zone-redundant storage accounts. Two other data centers have in-sync copies of the data if one data center burns down or is temporarily unavailable, e.g., due to power issues. Applications can continue to read or write to the Storage Account. No engineer has to intervene. In contrast, a data center failure can have severe consequences if a Storage Account is configured with local redundancy. The data becomes unavailable for read and write operations. If the data center does not come up again, all data is gone.
If an entire region fails due to a large-scale disaster, all Storage Accounts without a geo-redundancy option are temporarily or forever unavailable. Storage Accounts with geo-redundancy have a copy in a different region. In contrast to “normal” local or zone redundancy, geo-redundancy is not transparent. It might require application code adaption. Plus, the cloud staff has to perform failover and cleanup tasks.
Failover to the secondary region is an explicit decision of the customer. Its cloud staff must initiate the failover. Then, the secondary site becomes the new primary one though two aspects require attention. First, loss of data might occur. Microsoft has no formal SLA but mentions that the recovery point objective (RPO) is 15 minutes. In other words: data written in the last 15 minutes before the failure is lost. The application (and the business) must be able to cope with that. Second, Storage Accounts store their data only in one data center after the failover (local redundancy). Engineers have to reconfigure the Storage Accounts to reassure zone- or geo-redundancy. Eventually, they might want to move the data back to the original primary region.
When an entire region fails, this impacts applications even with the geo-redundancy option and even if the application code continues to run. Applications cannot read or write any data to or from their Storage Account in the primary region. Either the application code handles such circumstances (e.g., by showing users a “temporarily unavailable” page), or the application behaves unpredictably or crashes. Applications can reduce the impact on users with more sophisticated routines. The option to allow applications to read from secondary regions in case of a failure of the primary one enables applications to show users at least the currently available data. Writing changes is not possible – or only to another storage account not impacted; quite some work, but potentially worth the effort for highly business-critical applications.
To conclude: Azure offers a variety of configuration options for redundancy for Azure Storage Accounts, one of their most used services. Choosing an adequate option is an essential task for cloud architects. They have to balance the costs of the more sophisticated options with the actual availability needs based on the criticality of their applications.