
Database-as-a-Service (DBaaS) is one step for IT departments to focus on software development, configuring and integrating 3rd party solutions, and maintaining and optimizing application operations rather than spending time with infrastructure and middleware topics. But even DBaaS does not make backups obsolete. Certainly, engineers should not dump production databases, but what if they do it by mistake? Also, DBaaS does not come with a 100% availability guarantee, even though you can minizine risks with redundancy – but not every database might be worth such ongoing costs. So, what are the options?
In the following, we look at backup features for selected DBaaS offerings:
- Azure Cosmos DB
- Azure SQL Server
- Amazon DynamoDB
DBaaS implies that a web service provides database functionality via its API. Engineers and architects can only design backup strategies based on this API. So, what are the concrete features and options for the mentioned services?
Backups for Azure Cosmos DB
The backup options for most Cosmos DB variants – for NoSQL, MongoDB, Apache Casandra, Table, and Apache Gremlin, excluding PostgreSQL – are the same. For them, the first configuration decision is between continuous and periodic backup. A periodic backup means that at regular points in time, Azure performs a backup (Figure 1, A). Customers can set the periodicity to any value between 1 and 24 hours (Figure 1, B). The retention period can be up to 30 days (Figure 1, C). Azure keeps backups for so long; then Azure it them automatically. Alternatively, engineers can configure continuous backups (Figure 1, D). Then, they can roll back to any point in time within the last 7 or 30 days.
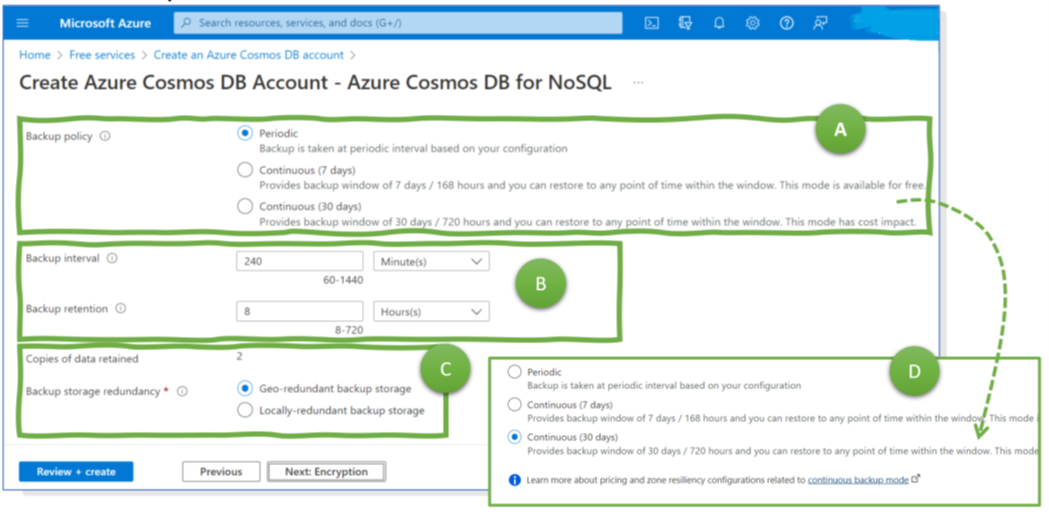
To prepare for more extensive outages, natural disasters, larger electricity blackouts, etc., Azure copies every backup by default to a paired region, such as from Switzerland (North) to Switzerland (West) or from France (Central) to France (South). If configured via CLI, options are geo-, zone-, and locally redundant storage. Self-service restores from the second region are not self-service but via service ticket and Microsoft support. Thus, larger events might result in a high volume of service requests and heavy delays for the restoration. Geo-redundancy for the service itself (not just for backups) can be necessary for business-critical applications.
Azure DB provides a sophisticated, easy-to-use solution for device failures (even the redundancy alone covers most cases) and operational mistakes, i.e., somebody realizes she deleted some data yesterday she did not intend to. There are shortcomings in other use cases:
- No support for ad-hoc backups. They are helpful, e.g., before deploying complicated patches that change the data model and data. Continuous backups cover them, but there is no option with periodic backups.
- The absolute limit of 30 days retention time can be too short, depending on the risk appetite and the setup. Cyberattackers might be in the system for a while unnoticed. Data manipulations not causing immediate issues might not be covered. Also, operational mistakes go unnoticed if data is only used monthly, quarterly, or yearly for, e.g., dedicated end-of-month, end-of-quarter, or end-of-year processing.
The statement is not that there are no solutions. Exporting data by script or restoring them into a different database instance might work. However, it is not an out-of-the-box feature. It requires customer engineering – or even the need for a 3rd party backup solution.
Backups for Azure SQL Server
Azure SQL server is a managed service – or a database-as-a-service – offered by Microsoft. While customers must make storage and server choices (unlike Cosmos, which scales up and down as needed), Microsofts performs (and automates) the database administration, including patching.
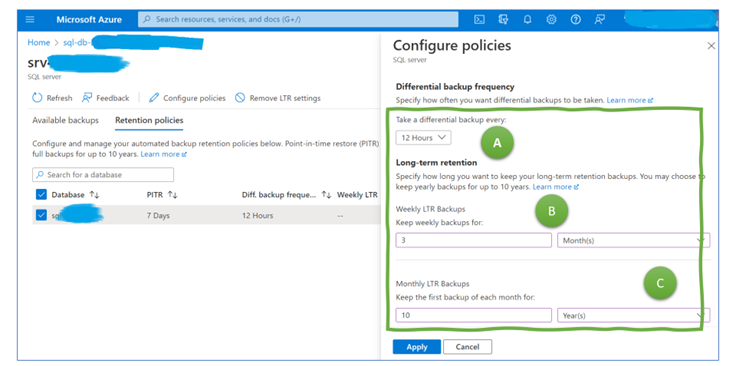
Azure SQL Server has point-in-time recovery, i.e., continuous backups enabling the restoration of the data of a specific point in time within the last 1 to 35 days. Internally, Azure performs full backups weekly and differential backups, depending on the configuration, every 12 or 24 hours (Figure 2, A). In addition, Azure backups transactional logs every 10 minutes. If the database crashes, a maximum of 10 minutes of processed transactions are lost. In other words, the Recovery Point Objective (RPO) is 10 minutes.
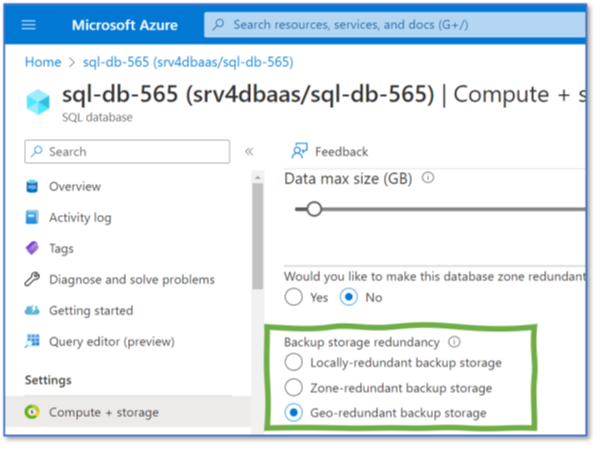
If engineers do not change the backup policy, backups are geo-redundant (Figure 3), i.e., copied to a paired zone, as discussed for the Cosmos DB. If customers have to rely on the geo-redundant copy, the RPO is 1 hour instead of 10 minutes.
A significant difference to Cosmos DB is the longer chance to put backup aside. A dedicated configuration option exists for how long to keep a weekly, monthly, and yearly backup – and the setting allows one to configure multiple years, not just some weeks.
The Azure documentation states that the restore time is usually “less than 12 hours”, though it might take considerably longer. Business-critical applications cannot rely on having a backup on the other side of the globe. They might have to configure the service itself as geo-redundant.
Backups for AWS Dynamo DB
Dynamo DB is a NoSQL database-as-a-service offering from AWS. Amazon fully integrated Dynamo DB with AWS Backup, AWS’s service for managing backups on an enterprise level. While there might also be legacy options, I focus on this backup functionality. After discussing two Azure services, the idea is to see how AWS approaches backups. And one difference was already mentioned: the full integration into the standard AWS backup solution.
For AWS Dynamo DB backups, the following paragraphs cover three aspects:
- Continuous backups for Point-in-Time Recovery (PITR)
- Ad-hoc Backups
- Periodic Backups
If explicitly enabled, point-in-time recovery based on continuous backups (Figure 4, A) is available in case of an issue. The retention time is 35 days, i.e., a restore to any given point within the last 35 days is possible.
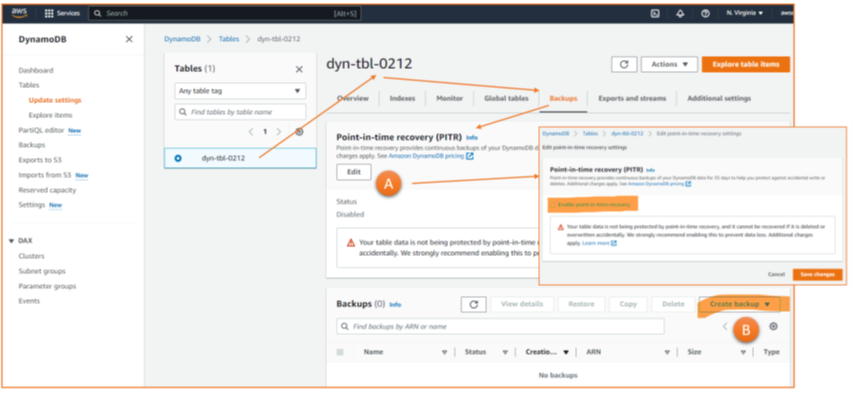
For ad-hoc backups, the first statement is: AWS provides the feature for Dynamo DB (Figure 5); there is no need for a workaround like in Azure. Engineers can configure some details – when it should start, how long it can take, in which vault to store it, and when to move it to cold storage – the most important being the retention time. When should AWS delete the backup? Here, the service allows choosing several years.
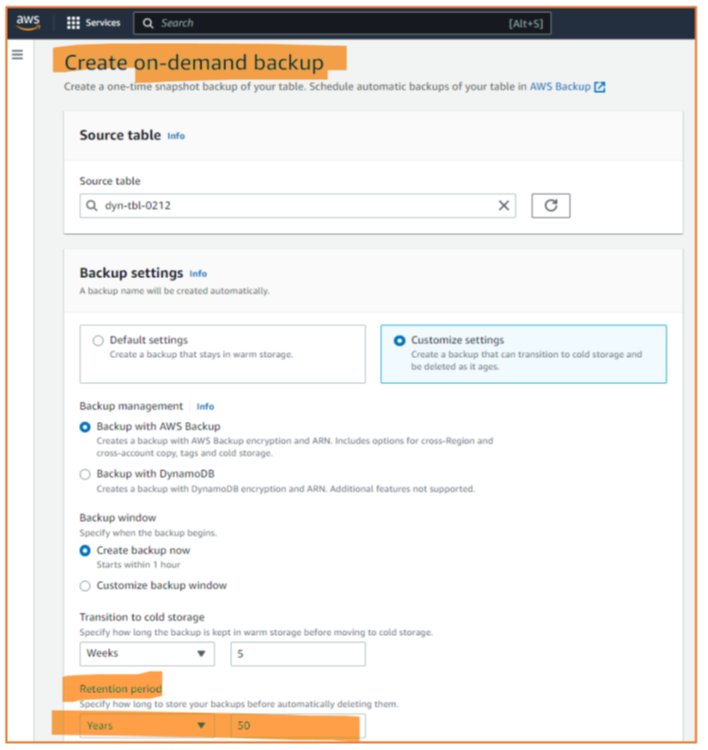
Finally, there is the option to schedule periodic backups. The configuration options are nearly the same as in Figure 5, though engineers must define the periodicity and the backup window for periodic backups. But why periodic backups when there is point-in-time recovery?
The main reason is that retention time point-in-time recovery of 35 days, whereas periodic backups can be kept for years. Other reasons – exotic ones – are: maybe cost savings, or maybe it is a legacy architectural design from before point-in-time recovery was available.
To conclude: The discussed database-as-a-service offerings from Azure and AWS all come with backup functionality, but they differ for all of them. Cloud and security architects do good when checking the company-internal backup requirements and policies and validating whether and how they can implement them. This validation is necessary per cloud and service.