Use Cases & Technologies
Cloud providers market their platform-as-a-service features, e.g., for AI or IoT. In contrast, many companies currently focus on moving their existing Windows and Linux applications into the cloud. “Lift-and-shift” is the motto. Rearchitecting is a task for later. As you might remember, neither the rise of C nor Java caused the immediate death of COBOL applications. Thus, in the cloud, the ability to backup IaaS workload is one of the most crucial topics when moving to the cloud – and AWS Backup is Amazon’s cloud-native solution for backups. How does it help?
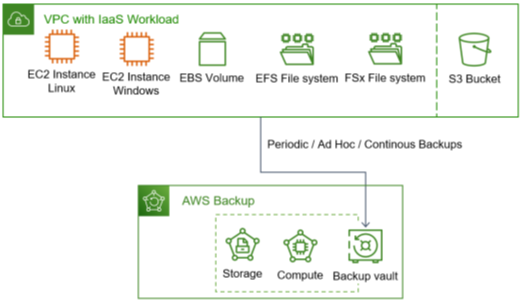
What does the workload look like, and which use cases should be supported? With the focus on IaaS, the VMs with their disks, file storage, and object storage are in place. The latter is a web service, but object storage is the new main storage variant in the cloud for new components configured or developed in a public cloud environment.
AWS Backup supports a long list of AWS services, including the following IaaS-related ones:
- EC2, AWS’s term for VMs
- Amazon Elastic Block Store (Amazon EBS), aka block storage for EC2 instances
- Amazon Elastic File System (Amazon EFS), a file system solution working with EC2 with Linux operating system, a technology typically needed by many traditional applications
- Amazon FSx supporting various file systems, including Windows File Server or NetApp ONTAP
- Amazon Simple Storage Service (Amazon S3) as the object storage service
So, this blog post covers how to organize backups for IaaS workload running on Windows and Linux EC2 instances with attached EBS volumes on which applications run relying on EFS and FX file systems for classic file storage, plus incorporating S3 buckets as the new dominant storage type in clouds. Figure 1 visualizes this.
Typical technical use cases for backup solutions are:
- Ad-hoc Backups, i.e., engineers make a manual copy before complex, risky changes
- Periodic Backups to prepare if something goes wrong and one has to restore a recent or long-ago state
- Continuous backups for Point-in-Time Recovery (PITR) as a solution covering both use cases above
AWS links to the solutions for 1 and 2 directly on the dashboard page for AWS in the AWS portal (Figure 2), whereas number 3 is part of the configuration options for 2.
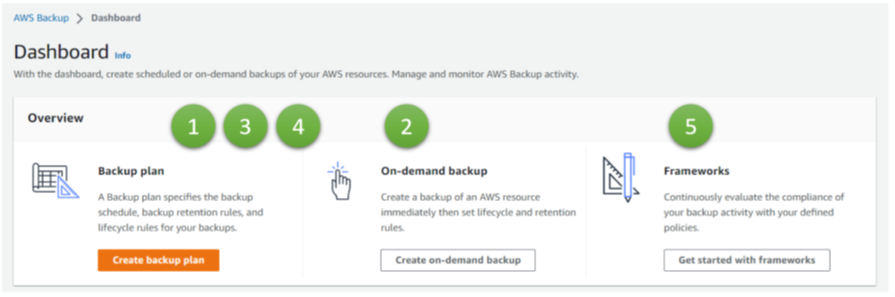
A fourth aspect is geo-redundancy, important for disaster recovery events, such as the loss of complete data centers or region-wide blackouts (4). Finally, we look at Frameworks, a governance and compliance tool (5).
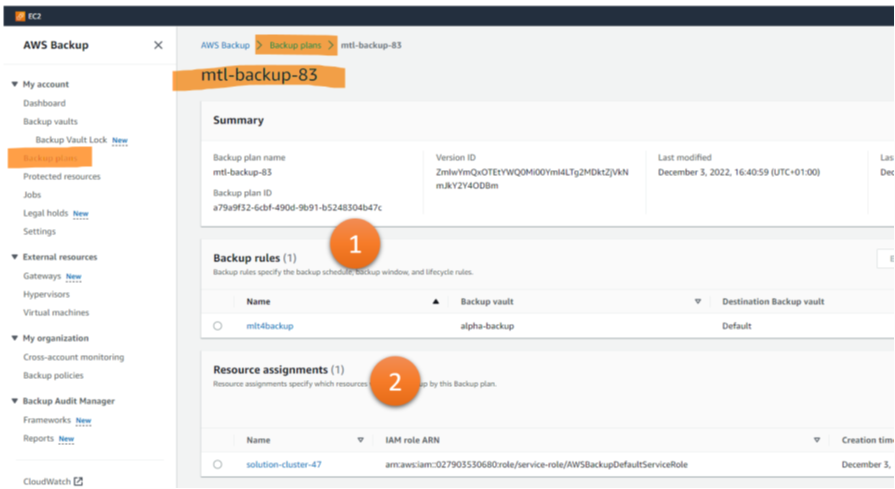
AWS Backup Plan
Setting up an AWS Backup Plan in AWS Backup means configuring one or more backup rules (Figure 3, 1) and one or more resource assignments (Figure 3, 2).
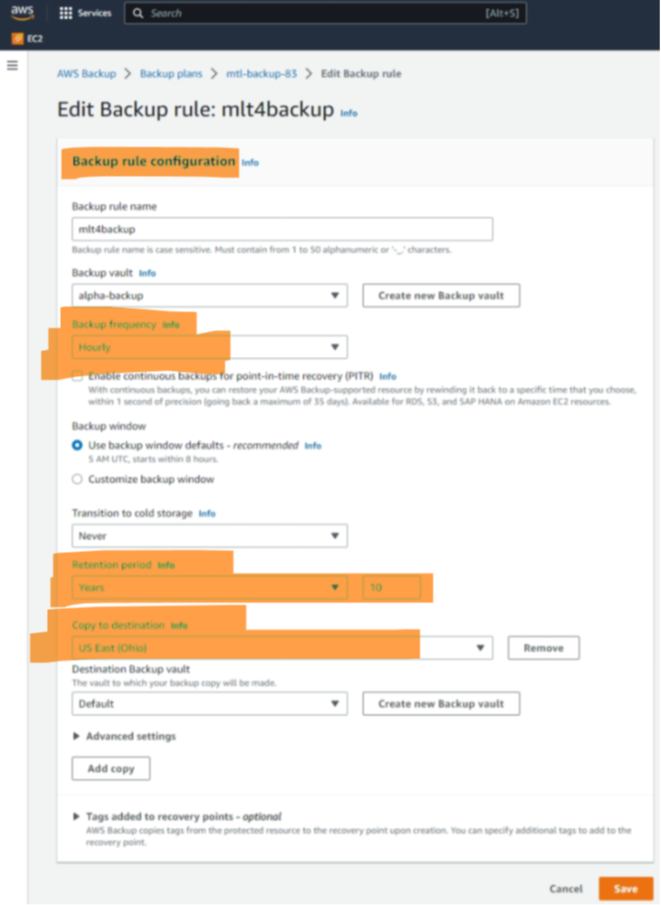
There are many ways to configure the various settings for backup rules. Thus, we focus on the settings for two scenarios. The first one is for periodic backups that have to be stored for years and which should be safe even in case of larger catastrophes. Thus, the configuration shown in Figure 4 sets the interval to four hours, whereas the retention time is 10 years, and a copy is stored in a different region than the original backup.
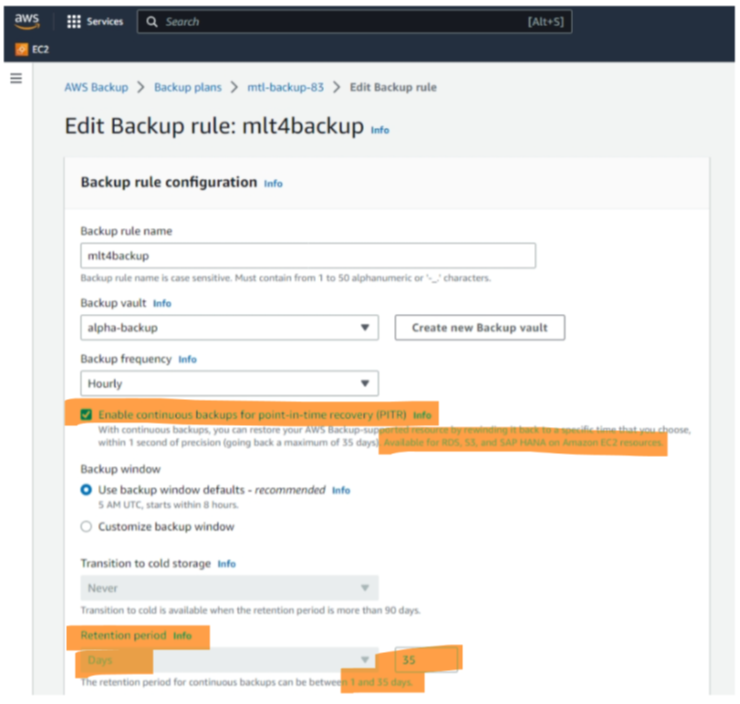
The second scenario is about backups needed for misconfigurations in operations. A wrong patch is deployed, an admin – by mistake – drops production data, etc. For this scenario, a continuous backup is perfect, allowing for point-in-time recovery (Figure 5). Just a warning: the fine print states that the continuous backup is available only for three AWS services: RDS, S3, and SAP Hana on EC2. For other services, the “hourly” periodicity counts. So, when looking at the IaaS services in AWS mentioned in the beginning, PITR is not available for EBS Volumes and EFS File Systems which are assigned to EC2 instances.
The resource assignment defines what is in scope for the backup. It allows filtering based on the resource type (e.g., EBS, S3) and tags assigned to resources (Figure 6). Once resource assignments and backup rules are defined, everything is ready, and Azure performs the (next) backup as specified in the rule.
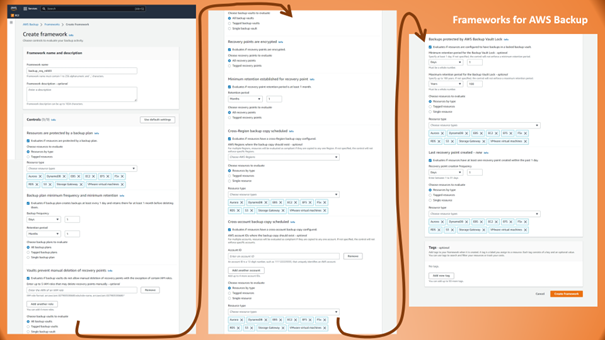
Frameworks for AWS Backup
Backups help bring up an application or a complete data center again when something goes severely wrong. However, if backups are missing in such an emergency, this is not just bad luck but a result of insufficient organization, governance, and oversight. AWS helps to prevent such situations by providing Frameworks for AWS Backups. They define the expected state (or configurations) for backups helping to identify a gap between how the world should be and how it is. It is a pretty exhaustive list, as Figure 3 illustrates.
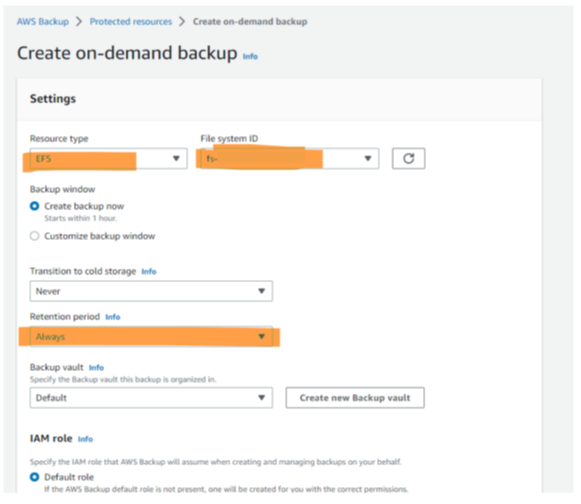
On-Demand Backups
On-demand backups are easy to configure and start in AWS: Choose the resource type and a concrete instance, make sure that the retention period is set correctly (remember: too many unnecessary backups require a lot of storage), and maybe define the vault to be used for storing the backup, and you are done (Figure 8).
The most notable aspect – besides that there is a single GUI for creating on-demand backups for all relevant services – is that one can back up just one instance of one resource. Sufficient for small applications, but for anything slightly complex, the tag-based definition of what is part of a backup (as known from the periodic backups) is much more efficient.
Additional Backup Services in AWS
AWS unites backup features for all resource types in the single AWS Backup GUI. Still, there are other options to make backups. Amazon Data Lifecycle Manager can back up EBS Volumes. The EFS-to-EFS backup solution is an option for file systems. And, S3 has a versioning feature allowing to restore previous versions of the object; it even has to be activated for backups. However, from a governance perspective, having all backups in one place – AWS Backup or a 3rd party solution – eases the governance. And do not forget: AWS Backup comes with this clever and easy-to-use feature for governance, AWS Backup Frameworks. Use it!