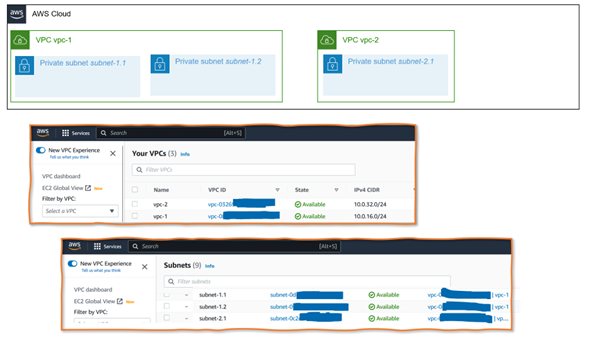
The concept of the Amazon Virtual Privat Cloud (VPC) and Subnets are the AWS terms for structuring the network. A VPC consists of a continuous IP address range represented by a CIDR block, e.g., 10.0.16.0/24. A network design with overlapping IP ranges for different VPCs is technically possible though it can result in issues when connecting, aka peering, such VPCs later.
The network design divides the IP range of a VPC further into Subnets. Subnets are the canvases into which engineers deploy VMs – EC2 instances in AWS speak, short for Elastic Compute Cloud (Figure 1). Subnets belonging to the same VPC must not have overlapping IP ranges, but they do not have to consume the complete range. Non-used IP ranges ease responding to changing business needs and IT landscapes. So, everything is similar to what we know from GCP and Azure. The way subnets are protected, however, differs slightly.
Figure 1: Network diagram with VPCs and Subnets and corresponding screens in the AWS GUI
Controlling Network Traffic with Network ACLs
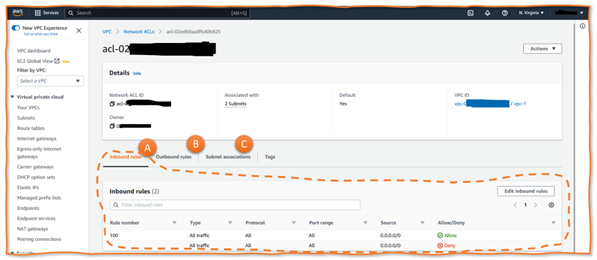
One AWS concept for securing the subnet perimeter is the Network Access Control Lists (Network ACLs) feature. Network ACLs allow or deny ingress and egress traffic. They act as a stateless firewall that checks traffic against a simple ruleset. Inbound rules (Figure 2, A) allow or deny traffic from specified IP addresses outside the subnet. Outbound rules (Figure 2, B) inspect traffic leaving the subnet. In addition to the source or target IP, rules can consider the port number (e.g., 23, 8080) and the protocol type. If there are conflicting rules, the priority of the rules is the deciding factor.
Figure 2: Sample Network ACL
When designing a concrete network, architects should be aware of default behavior and setups – and how Network ACLs, VPCs, and subnets relate. First, each VPC has a default Network ACL. It allows all ingress and egress traffic to and from the subnets within the VPC. However, the VPC (by default) has no connectivity with the internet, external networks, or other AWS VPC, be it in the same or another AWS account (we discuss this in the following section). Engineers can either change the default Network ACL or create a new one and associate it with one or more subnets of the same VPC.
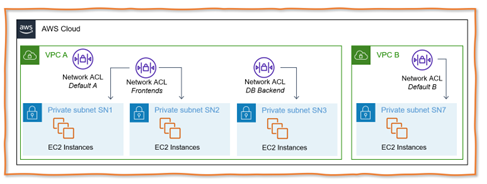
A simplistic example is a VPC hosting several web applications. Each application might have a frontend and a backend subnet. Frontend subnets have open HTTP and HTTPS ports plus an open JDBC port to connect to the database backend subnets, which allow only JDBC traffic. Figure 3 illustrates such a scenario. VPC A has a Network ACL “Frontends” associated with Subnets SN1 and SN2. There is a differenet second Network ACL “DB Backend” associated with Subnet SN3. VPC A has a default Network ACL, but it is not in use. In contrast, the default Network ACL for VPC B is associated with the only subnet there, SN7.
Figure 3: Understanding Network Access Control Lists NACLs) for AWS IaaS Workloads
Security Groups
In addition to Network ACLs, AWS provides a more sophisticated second feature for controlling network traffic: Security Groups. While Network ACLs impact the subnet perimeter, Security Groups focus on the traffic going through the network interfaces of individual VMs (or EC2 instances), for which AWS uses the term Elastic Network Interface (ENI). Applicable Security Groups can be configured per ENI. Each ENI must have at least one but can also have multiple Security Groups associated.
The rules for Security Groups specify the protocol as well as the source, respectively target IP addresses on the target with the following main differences:
Security Groups control traffic going through the ENI. Thus, they can also restrict traffic within a subnet, and different VMs within the same network can have different applicable Security Groups.
Security Groups act as stateful firewalls. Only the initiating in- or outbound traffic has to be allowed. Reply traffic is allowed automatically.
There are only “allow” rules, no “deny” rules. Adding an additional Security Group to a VM might result in more ports, protocols, and target or source IPs (or Security Groups) being allowed. Adding rules to Security Groups never restricts or forbids traffic.
By default, all outgoing traffic is allowed, and all incoming traffic is denied.
An important aspect from the security perspective is that EC2 instances can have secondary ENIs with a second IPv4 address which puts EC2 instances logically into two subnets. There are even more options in a world with IPv6.
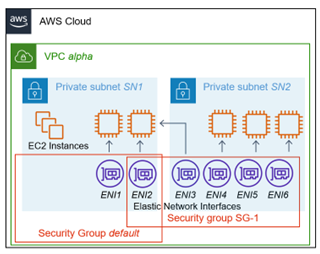
Figure 4 illustrates a network design with two subnets in one VPC with one default Security Group and a newly created second security group named SG-1. Both apply to the ENI2 network interface, whereas all other VMs only have one security group. The example also illustrates two network interfaces being attached to the same EC2 instance, which, as a result, becomes part of subnet SN1 and SN2.
Figure 4: Security Groups as Means of Protecting IaaS Workloads in AWS
Connecting VPCs with the Outside
A VPC without connectivity to other VPCs or the internet is securely protected against outside attacks – and completely useless. Suppose users, admins, customers, or other programs cannot start any processing because no one can reach the EC2 instances, and they cannot access outcomes and results. In that case, there is no need to have a VPC At least some EC2 instances, respectively, subnets and VPCs they belong to must interact with external servers and services. It creates an attack surface, but that is unavoidable and taggling the risks is part of the network security design.
VPC Peering is the essential concept enabling communication between VPCs belonging to the same AWS account or other AWS accounts within the same AWS organization. Components and VMs in peered VPCs interact as if they belong to the same VPC. All traffic stays internal. No traffic goes via the internet, keeping the attack surface low regarding outside attacks.
Shared VPCs are a similar concept. AWS accounts can share a VPC with other AWS accounts within the same AWS organization. Then, the other AWS accounts can create and manage components within this shared VPC. However, while everyone uses the same Shared VPC, resources of the different AWS accounts are managed and seen only by the AWS accounts to which they belong. AWS markets Shared VPCs as a feature to reduce the number of VPCs while still ensuring high interconnectivity, separate billing, and isolation or access control.
VPC Peering and Shared VPCs are powerful concepts but are limited to the IT landscape of one single company. However, Internet Gateways and NAT Gateways are key AWS features when companies interact with others. In this context, Architects have to understand: Do they need only traffic from within a subnet or VPC to the internet, or should EC2 instances be directly reachable from the internet? The latter, obviously, poses a higher attack surface and security risk since attackers can directly reach out to VMs.
Exposure to the internet requires EC2 instances to have a Public IP and the subnet/VPC to have an Internet Gateway component with a suitable routing table. Such a design allows ingress and egress traffic from and to the internet.
If EC2 instances only need to initiate egress traffic, a NAT Gateway is the solution. It takes invocations from EC2 instances within a subnet, routes them to external IPs, and sends replies back to the initiating EC2 instance. On the way, the NAT replaces the internal caller IP with its external IP and vice versa for replies.
AWS comes with various additional and less-frequently used concepts. Three features or services center around interactions between an on-premise and cloud infrastructure: AWS Virtual Private Network, AWS Direct Connect (dedicated, private connections), and AWS Transit Gateways (managing hybrid networks).
Finally, there is a connectivity or network feature named AWS Private Link. It is less relevant for the IaaS world of EC2 but crucial for application landscapes incorporating AWS PaaS and DBaaS services. I will cover the concept in one of my next posts.
PaaS services promise software engineers nothing less than effortless eternal happiness: a few clicks and you have ready-to-use, secure, and unlimited scalable cloud service, be it an AI, a database, or a super-exotic service. But do cloud providers deliver as promised? Is, for example, redundancy a child’s play? Redundancy is much trickier than backups. Backups are about having a copy of an application’s data for emergencies. In contrast, redundancy guarantees that the application runs 7×24. Even major disasters must not impact a solution’s stability.
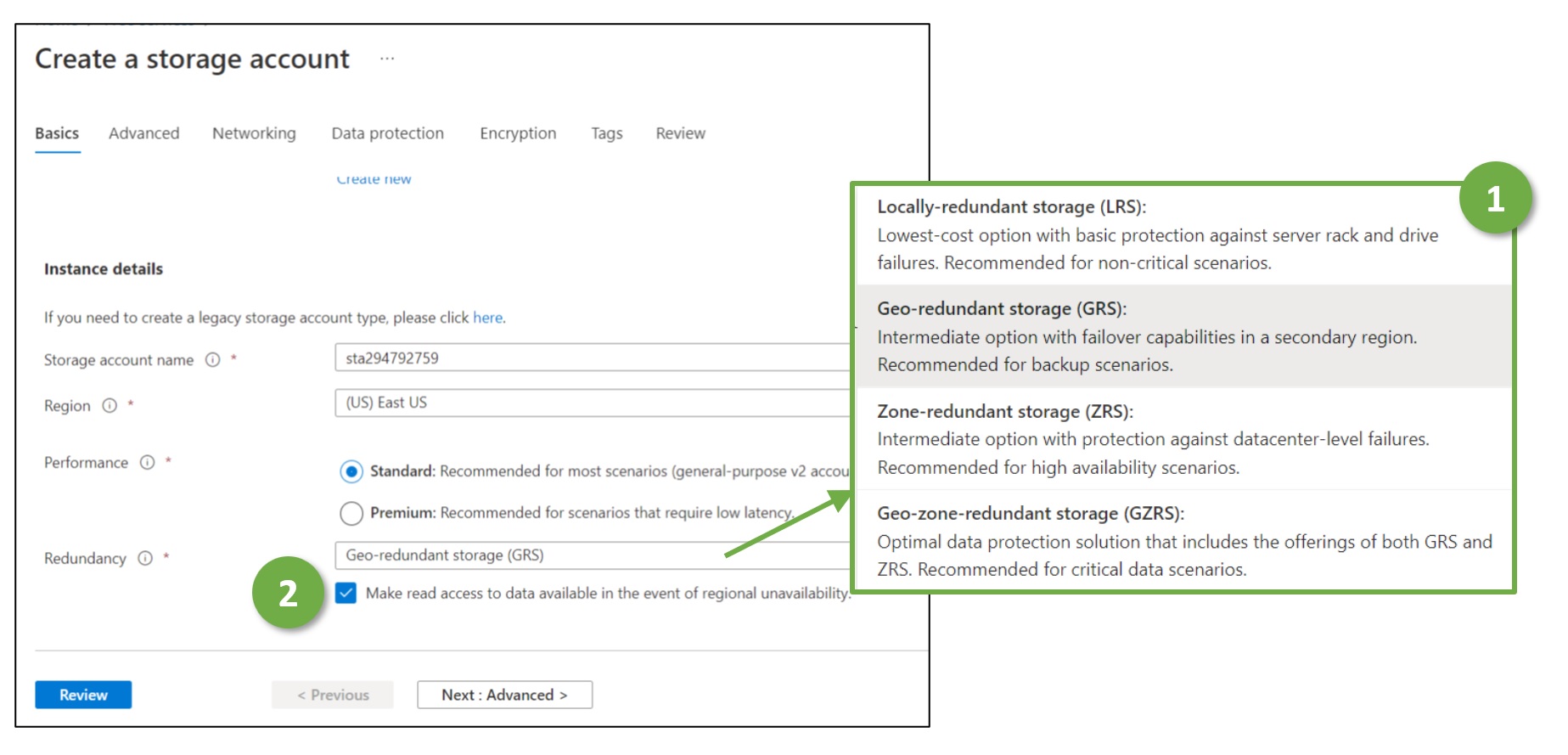
In the following, we look closely at one crucial Azure service, Azure Storage Accounts. It is Microsoft’s web service for storing data such as objects respectively, blobs, or files. We elaborate on which kind of disasters or failures the web service copes with – and how transparent it is from an application or operations perspective. Azure provides different options for configuring the recovery behavior of Storage Accounts (Figure 1), which the following paragraphs explain in more detail. Companies need specific guidelines on when to use which one – and writing such a guideline is a crucial cloud (security) architecture task.
Figure 1: Redundancy and Backup Options for Azure Storage Accounts – actual replication mechanisms (1) and read-feature for regional failure (2)
Cloud architects have to make (up to) three redundancy-related configuration decisions:
Should the data be replicated three times within one data center (local redundancy), or should there be a copy in three separate data centers (zone redundancy)?
Should there be copies in a data center further away in a secondary region (geo-redundancy)? For regulatory and compliance reasons, geo-redundant copies are usually in the same jurisdiction as the original data. Azure stores, e.g., geo-redundant copies for data in Switzerland-North (greater Zurich area) in the Azure region Switzerland-West around Geneva.
Should applications be allowed to read the geo-redundant copies if the primary region fails (“read access”)?
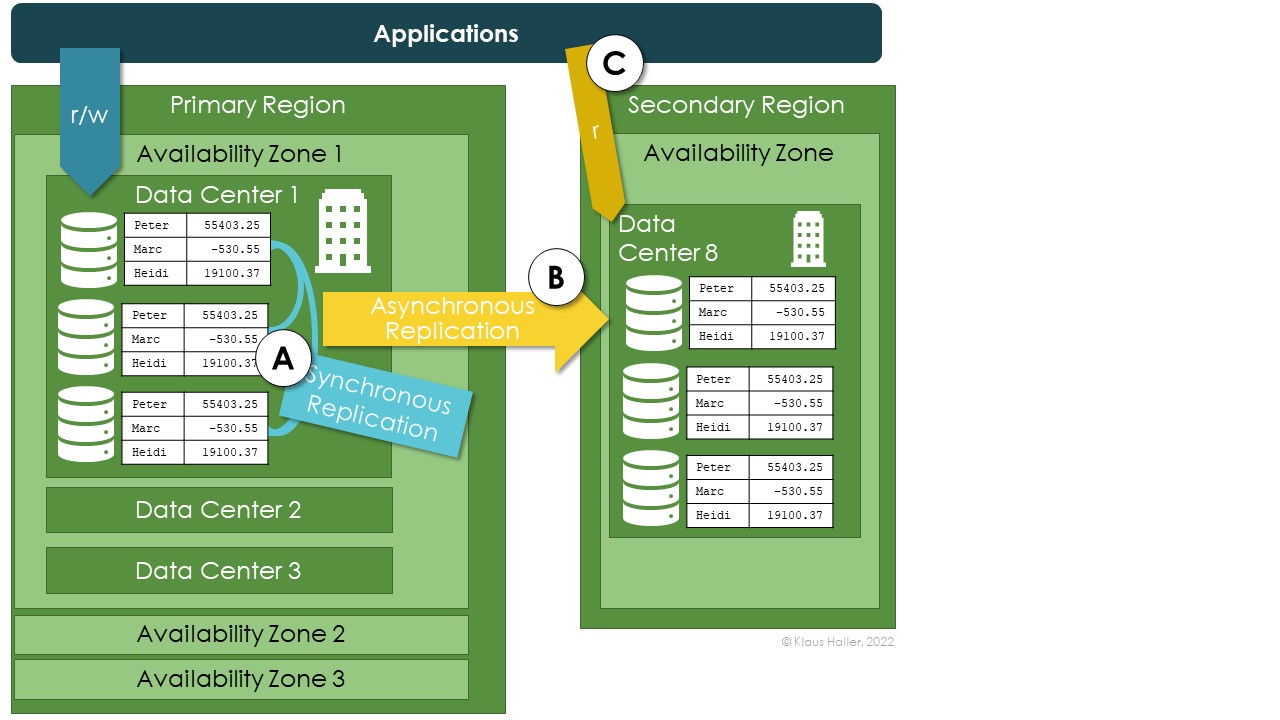
Figure 2 and Figure 3 illustrate the configuration options for a better understanding. The architecture in Figure 2 visualizes local redundancy. An application reads and writes data stored in one data center (A). The different copies are synchronously replicated and always in sync. If – and only if – the engineers choose the geo-redundant add-on, Azure replicates the data asynchronously to one data center in a secondary region (B). In such a case, the Storage Account can be configured to allow applications to read from the storage account in the secondary region if the first region is unavailable (C).
Figure 2: Azure Storage Account with Local-Redundancy Option
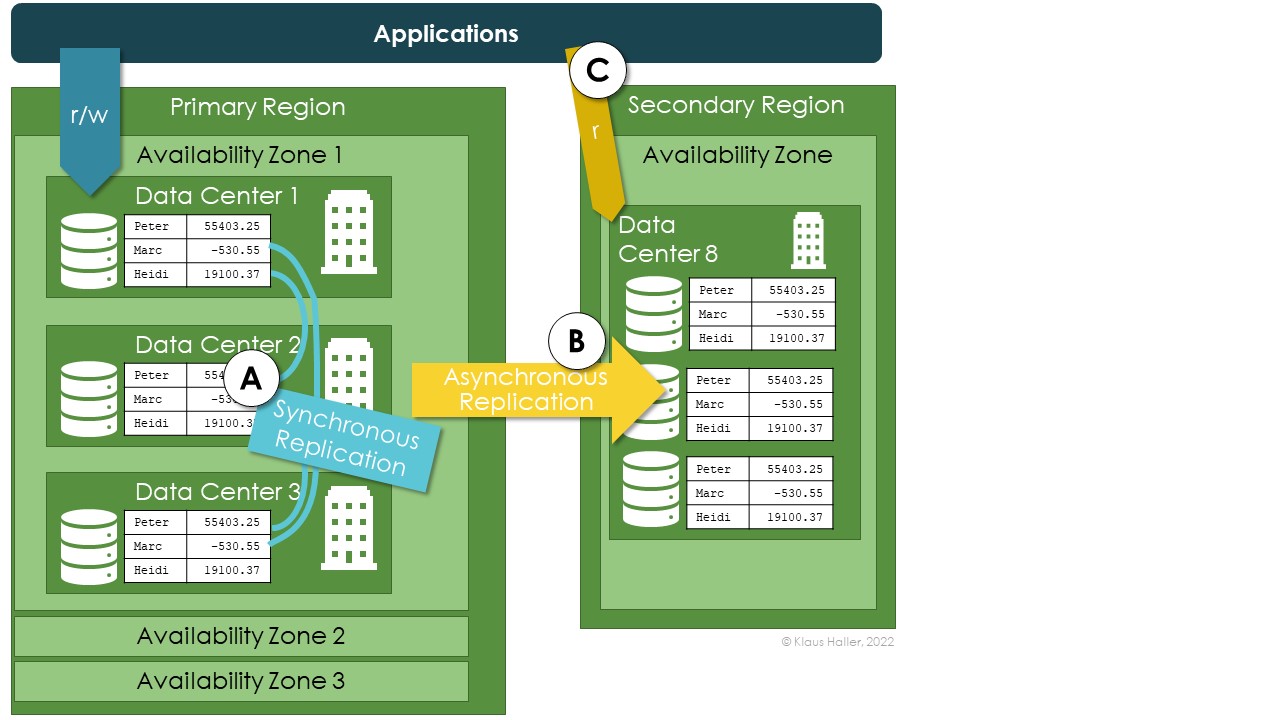
Figure 3 looks very similar. It illustrates zone-redundancy. In such a set-up, the three copies are in different data centers in the primary region (A). If geo-redundancy is active, all asynchronous copies in the secondary are stored in the same single data center (B)as in the previous case in Figure 2. Applications can get read access in case of unavailability of the primary region – as with local redundancy (C).
Figure 3: Azure Storage Account with Zone-Redundancy Option
In the next step, we look closer at three failure scenarios: a failure of a single device, a data center, and an entire region. Which configuration option allows the application to continue to run? How transparent are such incidents for applications? What does the cloud operations team or the applications team have to do?
First, a failure of a single device in a data center has no impact on any application or operational staff. Azure always maintains three up-to-date copies of any data, be it in one or be it in three data centers. These copies are always in sync. Thus, if a device fails, another device in the same or another data center takes over and has precisely the same data. There is neither data loss nor interruption of application availability, nor any necessity for manual interventions.
A failure of a complete data center is transparent for zone-redundant storage accounts. Two other data centers have in-sync copies of the data if one data center burns down or is temporarily unavailable, e.g., due to power issues. Applications can continue to read or write to the Storage Account. No engineer has to intervene. In contrast, a data center failure can have severe consequences if a Storage Account is configured with local redundancy. The data becomes unavailable for read and write operations. If the data center does not come up again, all data is gone.
If an entire region fails due to a large-scale disaster, all Storage Accounts without a geo-redundancy option are temporarily or forever unavailable. Storage Accounts with geo-redundancy have a copy in a different region. In contrast to “normal” local or zone redundancy, geo-redundancy is not transparent. It might require application code adaption. Plus, the cloud staff has to perform failover and cleanup tasks.
Failover to the secondary region is an explicit decision of the customer. Its cloud staff must initiate the failover. Then, the secondary site becomes the new primary one though two aspects require attention. First, loss of data might occur. Microsoft has no formal SLA but mentions that the recovery point objective (RPO) is 15 minutes. In other words: data written in the last 15 minutes before the failure is lost. The application (and the business) must be able to cope with that. Second, Storage Accounts store their data only in one data center after the failover (local redundancy). Engineers have to reconfigure the Storage Accounts to reassure zone- or geo-redundancy. Eventually, they might want to move the data back to the original primary region.
When an entire region fails, this impacts applications even with the geo-redundancy option and even if the application code continues to run. Applications cannot read or write any data to or from their Storage Account in the primary region. Either the application code handles such circumstances (e.g., by showing users a “temporarily unavailable” page), or the application behaves unpredictably or crashes. Applications can reduce the impact on users with more sophisticated routines. The option to allow applications to read from secondary regions in case of a failure of the primary one enables applications to show users at least the currently available data. Writing changes is not possible – or only to another storage account not impacted; quite some work, but potentially worth the effort for highly business-critical applications.
To conclude: Azure offers a variety of configuration options for redundancy for Azure Storage Accounts, one of their most used services. Choosing an adequate option is an essential task for cloud architects. They have to balance the costs of the more sophisticated options with the actual availability needs based on the criticality of their applications.
Serverless application logic, storage accounts, platform-as-a-service identity and access management, this small tutorial combines state-of-the-art Azure technologies in a four-step demo or tutorial. The result: a serverless Azure Function invoked via a web browser that returns a welcome text, which the Azure Function reads from an Azure Storage account using Azure Identity for authentication and authorization.
Prerequisites for performing this tutorial are:
An Azure cloud account (we use only free services)
A local Visual Studio installation (free version sufficient)
Setting up the Azure Storage Account backend
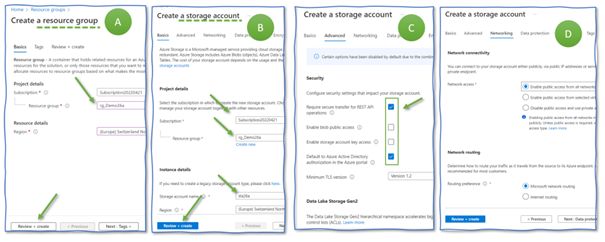
Create a resource group named “rg_Demo26a” (Figure 1, A). The resource group collects and stores all the resources we create in the following. Having all resources in a dedicated resource group eases cleaning them up after completing this demo.
Next, create an Azure Storage account “sta26a” (Figure 1, B) in the resource group “rg_Demo26a”. On the “advanced” tab, disable public access and storage account key access and enable default Azure Active Directory authorization (C). Then, advance to the “networking” tab. Here, make sure to have “enable public access” activated (D). This setting means that our storage is directly connected to the Internet and only protected by access management methods. It is a dangerous setting, though it saves us time in the demo. Never do this in any Azure subscription used for anything but for playing around.
Figure 1: Creating a Resource Group and an Azure Storage Account
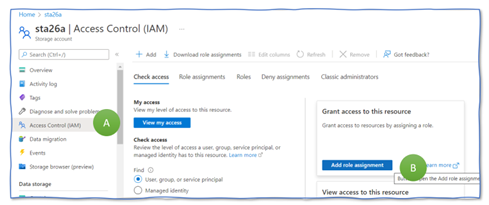
Creating a Storage account does not allow you to upload or read files. Thus, before actually uploading any file to the Storage Account, you need to grant yourself “Contributor” rights for the Storage Account. Therefore, go to your Storage Account “sta26a”, select “Access Control (IAM)” in the menu to the left (Figure 2, A), and push the “Add role assignment” button (B).
Figure 2: Starting a role assignment
Then, search for roles containing “blob” (Figure 3, A), select the role “Storage Blob Data Contributor” (B), and click “next” (C) to proceed to the next submask. Here, choose “user, grout” for the “Assign access to“ setting (D) and click on “sel3ect members” (E). A new submask appears to the right. It presents the users of this Azure tenant. Select the user you are currently logged in (F) and have a coffee afterward. It takes a few minutes until the new rights are active. If you proceed too early, the next step fails.
Figure 3: The actual role assignment to an AAD registered user
Now you are ready to upload a file. Create a text file “output.txt” on your laptop with the content “Hello world, hello Klaus!”. Upload this file into our Azure Storage Account.
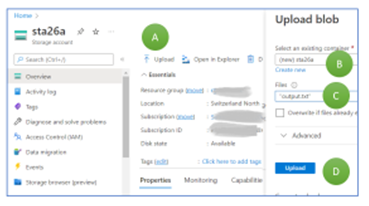
Switch to the newly created Storage Account and select “upload” (Figure 4, A). Select “Create new” and type in “cont26a” as container name (B). Open the file explorer by clicking on the symbol to the right. Select the file we just created (C). Then, press “Upload” to load the file “output.txt” to the cloud (D). If the upload button is not blue, something went wrong in any of the previous steps.
Figure 4: Creating a container and uploading a file to an Azure Storage Account.
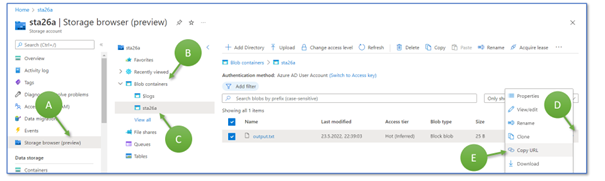
As a last step in the Azure Portal, for now, open the Storage Account sta26 and select the storage browser (A). Click on the blob containers (B), then on “sta26a” (C). You see the list of files stored there. Click on the three points at the right of the row “output.txt” (D) and click “Copy URL” (E). Paste the URL in some document or file. You need the string in half an hour. Then, for the next step, switch to Visual Studio.
Figure 5: Retrieving the URL of a file stored in an Azure Storage Account
Creating an Azure Function
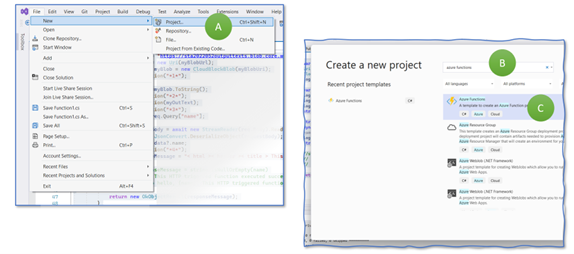
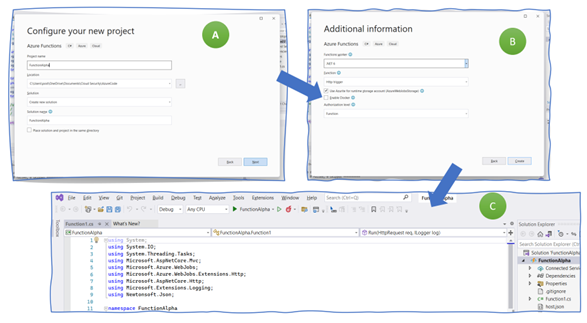
We create, first, a simple predefined Azure Function and deploy it to the cloud. It does not connect to our Storage Account. The step is more for verifying that the overall setup is correct. In VisualStudio, select “File > New > Project” (Figure 5, A). VisualStudio will propose various templates. Type in “Functions” into the search field (B), select “Azure Functions,” and continue (C). If you do not find this template, you can install missing ones after clicking on “Not finding what you are looking for? Install more tools and features” and search for “Azure development”.
Figure 6: Starting to create an Azure Function project
The next mask asks you for a function name (use “FunctionAlpha”) and a location where to save your files (Figure 6, A). Then comes the “additional information” tab. Select “.NET 6” and “http trigger” as the function you want to get created. Make sure that the other settings are as in figure (B): select “Use Azure,” deselect “Docker,” and use the function scope as authorization level. As a result, VisualStudio creates a simple function that returns some output when invoked.
Figure 7: Configuring and creating the http listener example
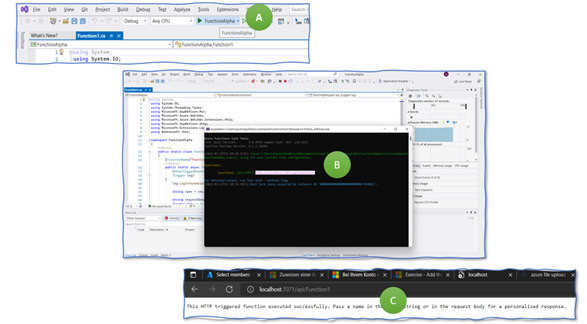
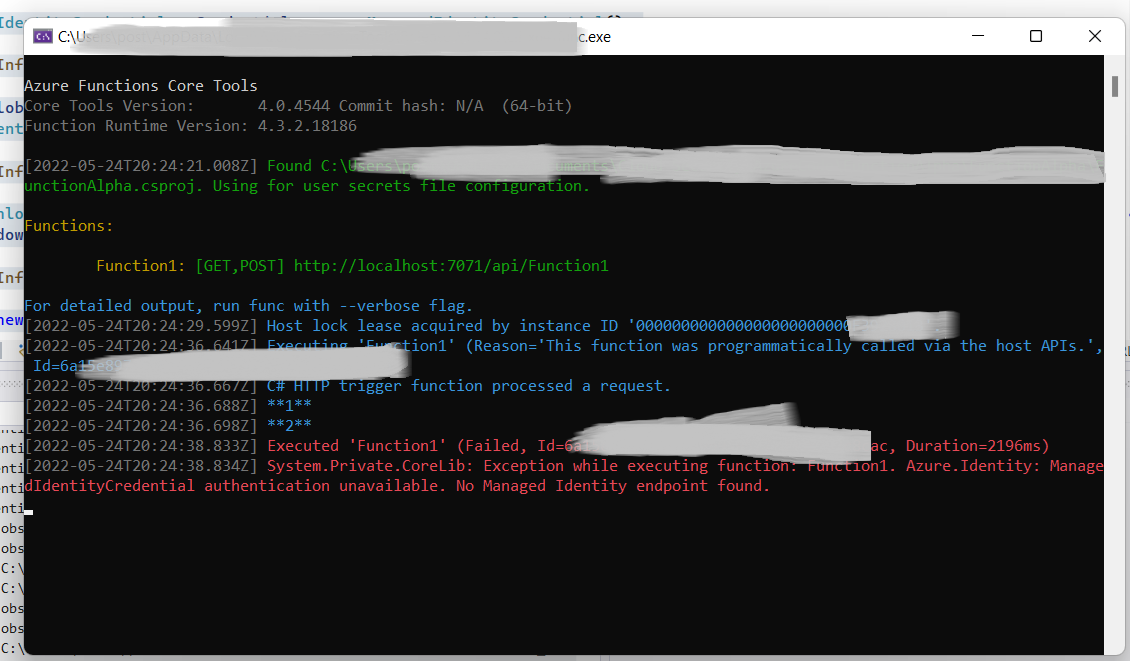
We execute the code now locally on your laptop. Run the function by clicking on “FunctionAlpha” next to a green triangular on the menu to the top (Figure 6, A). A new window opens up, in which the listener process runs. This process waits for incoming http requests. To send a request, copy the URL provided in the window (B) and paste it into a web browser window. You should get the output as shown in the figure (C).
We now know that the function works locally on the laptop. Next, we deploy this function to an Azure runtime environment so that the function runs – serverless – in the cloud.
Deploying and Invoking an Azure Function
Azure comes with a feature to structure your functions – you do not create an Azure Function directly in a resource group but collect them in one or more Azure Function Apps. Create one in the Azure portal (Figure 8, A). Use resource group “rg_26a” and type in “FunctionApp26a” as the name for the Function App. Select “Code” as the way of publishing, “.NET” as runtime stack, “6” as the version, and “Windows” as the operating system. On the next mask (B), choose to create a new storage account and type in “stafa26a” as its name. Select “review and create” and start the creation process.
Wait until you see that the resource has been created (C).
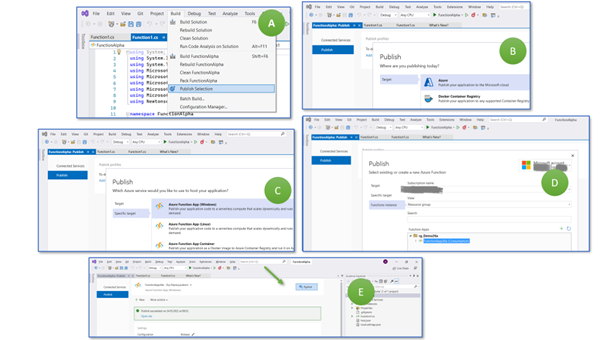
To deploy the function to the Azure cloud, select “Build > Publish Selection” (Figure 8, B), then “Azure” as target (B), and “Azure Function App (Windows)” (C). Finally, choose your subscription, then select the resource group “rg_Demo26a” and the recently created Azure Function App “FunctionApp26a” (D). Continue and wait for the (quick) configurations to take place.
You might think you are done. I thought precisely the same several times. However, you have to go back to “Build > Publish Selection” and click the publish button (E).
Figure 10: Deploying an Azure Function prepared in Visual Studio to the Azure Cloud.
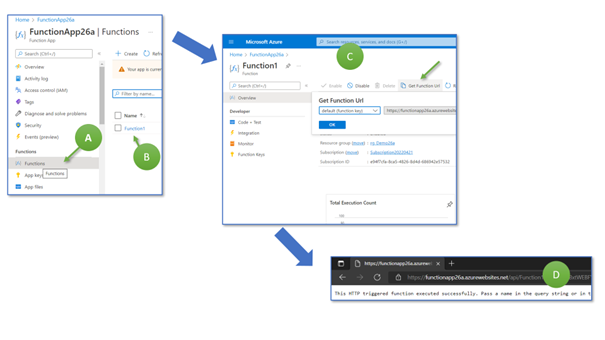
Now, switch back to the Azure Portal. In the Azure Function App screen, we choose “Functions” in the menu bar to the left (A). We now see our function with the name “Function 1” (B). Click on the name to open the details page, where you can retrieve the web function’s URL (C). Click on “Get Function URL,” copy the link, and paste it into a web browser (D).
Figure 11: Invoking the Azure Function deployed in the Azure Cloud
Connecting the Worlds …
We have created a Storage Account with one text file that our function should display when invoked via an internet browser. Therefore, we modify the function and read the welcome text from the Storage Account.
Open Visual Studio again and replace the Azure Function code with the following (check and update the blob URL if necessary):
using system;
using system.Threading.Tasks;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.WebJobs.Extensions.Http;
using Microsoft.AspNetCore.Http;
using Microsoft.Extensions.Logging;
using Azure.Storage.Blobs;
using Azure.Storage.Blobs.Models;
using Azure.Identity;
namespace FunctionAlpha
{
public static class Function1
{
[FunctionName("Function1")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
ManagedIdentityCredential myCredentials = new ManagedIdentityCredential();
log.LogInformation("**1**");
var myBlobUrl = "https://sta26a.blob.core.windows.net/sta26a/output.txt";
BlobClient bc = new BlobClient(new Uri(myBlobUrl), myCredentials);
log.LogInformation("**2**");
BlobDownloadResult downloadResult = await bc.DownloadContentAsync();
string downloadedData = downloadResult.Content.ToString();
log.LogInformation("**3**");
return new OkObjectResult("Output text from file in the cloud: "+ downloadedData);
}
}
}
Save the file, run it locally, and invoke it as before in Figure 8. Now you should get an error message in the browser; the listener process should display an error message (see Figure 12).
Figure 12: Invoking the Azure Function accessing a blob in an Azure Storage account from a local laptop – without proper access rights
Next, deploy the updated Azure Function to the Azure Cloud, following the steps already shown in Figure 10. Then, run the function as illustrated in Figure 11. The result is another error message (HTTP Error 500), as Figure 13 illustrates. The exact text depends on your browser and the browser (language) settings.
Figure 13: Failing invocation of the updated Azure Function, resulting in an HTTP ERROR 500
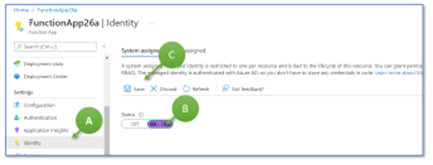
The reason is simple: the Azure Function still has no read access to the file in the Azure Storage Account. To reach this aim, we have to switch on the system-assigned managed identity for our Azure Function App “FunctionApp26a”. Go to this Function App and select “Identity” in the menu bar to the left (Figure 14, A), change the status to “on” (B), and save the change (C).
Now, we do one final reconfiguration add grant the function’s managed identity read access to the storage account. Therefore, switch to the storage account “sta26a” (Figure 15, A), open “Access Control (IAM)” (B), and click on “add role assignment” (C).
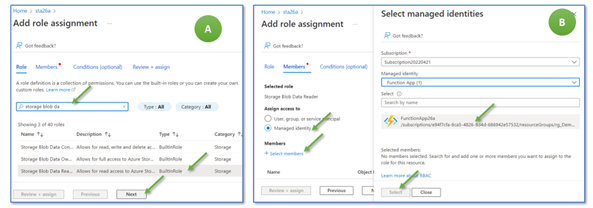
On the next mask, search for the “Storage Blob Data Reader” role and click on “next” (Figure 16, A). On the next mask (B), select “Managed Identity,” click on “+ Select members,” and select “FunctionApp26a”. Then, click on “Select” and “Review + assign.”
Figure 16: Assigning a role to an Azure Managed Identity
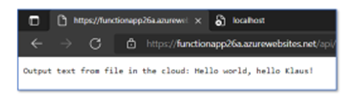
Now copy the Azure Function’s URL again into a web browser. Be sure to retrieve the full URL, not just the beginning. If your URL looks like https://functionapp26a.azurewebsites.net/api/Function1, it will fail. It should look like https://functionapp26a.azurewebsites.net/api/Function1?code=**SOME-STRAGE-CHARACTERS**==. The result should look like Figure 17. If so, you made it. Time to celebrate!
Figure 17: Finally, what you should see at the end of the tutorial. The Azure Function retrieves text from the Azure Storage Account and returns it
With all the efficient and innovative Platform-as-a-Service (PaaS) services in the cloud world, a catastrophe is only one click away. An engineer wrongly configures a database or object storage service, and cybercriminals have access to all data from anywhere on the internet. Booz Allen Hamilton, WWE, Verizon Wireless, Accenture, the Pentagon: these are just some prominent companies and organizations that misconfigured their AWS S3 object storage and lost millions of data records. So, how can cloud security architects avert such catastrophes?
The article exemplifies typical but risky configuration options in Microsoft’s Azure and the Google Cloud Platform (GCP). Then, its focus shifts to Azure’s concepts of Private Endpoints and Private Links and to GPC Service Controls. Looking at the different features of the two sample public cloud providers allows for a better understanding of the various security risks and mitigation approaches when protecting PaaS services.
Basic PaaS Configurations
When creating PaaS service instances via the GUI, the cloud vendors usually suggest (also) security configuration options with a relaxed security level. Their motto: simple and easy to set up, every engineer trying out the cloud and a specific service should succeed. But such configurations come with risks that this section elaborates on in more detail.
In classic data centers, a solution can invoke internal web or microservices only if meeting two conditions:
Authentication (and authorization), i.e., only specific applications, solutions, and users can invoke the service after verifying their identity and when they have the needed access rights and roles.
Reachability of the service in the network: Networks are typically divided into different zones, separated by firewalls. Invoking services in different zones requires opening up connections.
PaaS service default configurations usually require authentication but come with limited network-level protection. By default, PaaS services belong to one zone: the worldwide internet, where everybody can reach everything.
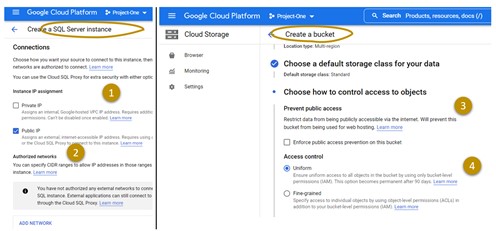
Figure 1 illustrates the network security configurations when creating instances for two typical GCP PaaS services: Cloud Storage, Google’s object storage service, and managed SQL database instances. When engineers create a database service in GCP, they have to choose between a public and a private IP address (Figure 1, 1). A public IP means that everyone on the internet can connect to this service. If the authentication mechanisms are in place and configured correctly and if attackers cannot get access keys etc., this is a perfectly safe approach. However, it is a challenge to ensure that none of hundreds or thousands of engineers in a larger IT organization ever make a critical mistake. And indeed, Goole provides the option to restrict access to certain network zones to reduce the risk (Figure 1, 2).
Figure 1: GCP PaaS Services for storing data. Network security settings when creating SQL Server (left) and Cloud Storage instances (right)
When creating a Cloud Storage bucket, engineers must decide whether to enforce the prevention of public access to the data stored in this bucket. The challenges with any object storage are – be it in GCP, Azure, AWS, or any other cloud – contradicting network security needs for the two primary use cases.
The first use case for object storage is storing classic (internal) application data. An archiving system might store Pdf files, security solutions potentially video recordings that document who performed which command on a particular system. Such data must not be made available to the internet. The perfect security setting preventing for such an object storage service instance is “forbid all internet access.”
The second use case for object storage is storing and delivering websites, e.g., a web page with an interview text plus incorporated pictures. Everyone on the internet should be able to access the web pages and read the interview. There is no need for network firewalls or authentication mechanisms.
So, there are two highly relevant use cases, and one technology solves both needs and challenges. That is, usually, perfect, just not in this case. In this peculiar case, it is a security risk. When you configure the object storage for a bank’s know-your-customer documents by mistake as publicly accessible website storage, you might only notice when your documents appear for sale in the darknet.
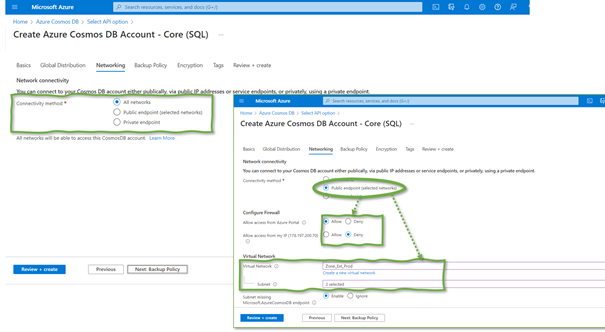
Public IPs and the risk of misconfiguration is not a GCP specialty. Figure 2 presents a GUI mask for creating a Cosmos DB database service via the Azure portal. Two settings create public endpoints: “all networks” and “public endpoint (selected networks).” Especially in the case of “all networks,” anyone on the internet can reach the Cosmos service instance. In other words, access control misconfigurations can have catastrophic results.
To point out the situation clearly – and this is the same for GCP Cosmos DB or Azure SQL databases and many more database services in the cloud – there is no sensible reason why databases should have a public IP. Databases are backend systems. There is no point reaching them from outside the organization.
The screenshot in Figure 2 has a third option for Cosmos DB: Private Endpoints. The following section looks at the details.
Figure 2: Network security options when creating a Cosmos DB
Azure Private Endpoint and Link
Some time ago, Azure introduced Private Endpoints and Private Links. They provide an extra layer of security. Thanks to them, engineers can incorporate PaaS service instances (e.g., Cosmos databases) into a VNet and access PaaS services without going via public IPs. When creating a Cosmos Database Service instance with this option, engineers create a Private Endpoint in their VNet with a VNet-internal, private, non-public IP. The Private Endpoint points to the actual resource, e.g., a Cosmos Database, via a Private Link.
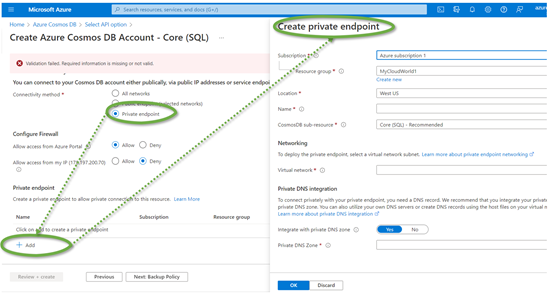
“Private Endpoint” is the third connectivity option in the example of creating a Cosmos service instance (Figure 3). When chosen, engineers can create and add a private endpoint. The Private Endpoint has a name – and the engineer specifies into which VNet Azure shall deploy the Private Endpoint.
Figure 3: Private Endpoint configuration option for Azure Cosmos DB
Figure 4 illustrates what happens in the background in the case of a private endpoint / private link connectivity (B) versus the traditional approach (A).
In addition to configuring Azure Private Endpoints and Private Links, engineers must be aware of and mitigate two more risks. First, Private Links and Private Endpoints are for themselves save, but the cloud architecture must ensure no firewalls are open on the resource itself (risk C). The benefit is that there is no need to open a firewall to make solutions work and components interact. Thus, forbidding opening ports gets feasible. Second, criminal employees might try to exfiltrate data. They could send company data to a personal Cosmos Database service instance controlled and owned by themselves as private persons (D). Cloud security architects can demand that all traffic to storage or database services goes via Azure Private Endpoints thanks to Private Endpoints and Private Links. Auditing and analyzing networks for exfiltration paths gets much more straightforward.
Figure 4: Classic PaaS Connectivity (A) versus Private Endpoint / Private Link (B). C and D illustrate remaining network security risks for Private Endpoint and Private LInks.
Before discussing Google’s real cool feature for PaaS perimeter protection, a final remark about Azure Private Links. Azure Private Link Service enables engineers to make their own services and resources available via Azure Private Endpoints. Thereby, they benefit from the same security features for their code that Microsoft relies on for protecting its Azure PaaS services.
GCP Perimeter Protection with VPC Service Controls
Google’s VPC Service Controls concept enables cloud security architects to build a perimeter-protected network zone composed of IaaS and (!) PaaS resources. A VPC Service Control definition comprises five main elements: projects, services in scope, accessible services, access level, and traffic exceptions.
The GCP projects of a VPC Service Control define the trust perimeter. These projects trust each other and can freely interact as defined by the network configurations. In contrast, applications in other VPC Service Control perimeters must not access the resources if not permitted explicitly.
The GCPServices part of a VPC Service Control definition specifies for which services the perimeter protection of the VPC Service Control applies. That is a crucial setting. If, for example, Cloud Storage is not part of the perimeter definition, engineers can easily transfer data in and out of the VPC Service Control perimeter. A note: Google adds the feature to more and more services, but it might not yet be available for all needed by a company. Thus, disabling unprotectable GCP services can e a necessity.
GCP Accessible Services add another nuance to perimeter definitions. The feature enables engineers to limit the GCP services, which resources can invoke within the Service Control perimeter.
As a result of a VPC Service Control definition, services respectively their callability fall into three categories:
Service instances of GCP services under VPC Service Control perimeter protection. They are only accessible from within the perimeter. Plus, they cannot invoke external service instances.
Service instances of GCP services without restriction. VMs within a VPC Service Control can connect to VPC-internal and external service instances. Plus, VPC external resources can (try to) connect to VPC-internal instances of this type.
Services blocked for use within a VPC Service Control (“GCP Accessible Services”) setting.
The GCP Access Level is an option for context-aware authentication and authorization. It is a new and upcoming approach requiring a detailed analysis worth a dedicated article.
A last core element is an option for defining exceptions, i.e., adding ingress and egress trafficrules allowing otherwise not allowed traffic into and out of the VPC Service Control. Thus, VMs from within one service parameter might get read access to Cloud Storage in a different service perimeter.
VPC Service Controls in the GCP world and the Azure Private Link/Private Endpoint help cloud security architects shield PaaS (and IaaS) service instances from the internet or other internal network zones. Their absoluteness – especially the exceptionally rigid VPC Service Controls – is what makes them so valuable. No one has to define, analyze, and manage thousands of rules and exceptions to understand and ensure the overall security posture of a network consisting of IaaS and PaaS resources. Instead, PaaS security becomes (nearly) a child’s play.
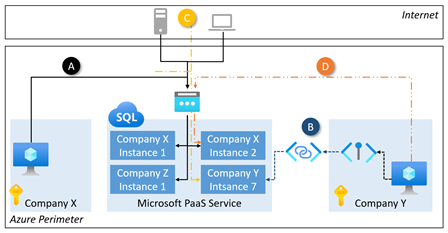
Commonalities and differences between securing VM-based Workloads on Microsoft Azure and the Google Cloud Platform (GCP)
When moving from an on-premises data center to the cloud, architecting and engineering a secure network is the first challenge. The days of buying hardware and wiring devices are over. Instead, cloud network engineers configure the network with templates and web GUIs. A secure network setup reflects three needs:
Workload structuring and separation, i.e., the high-level network design
Fine-grain connectivity and security controls
Enabling intra- and inter-company interactions between systems, applications, and components
For these three areas, we answer the following questions. First, which network architectural features do cloud vendors offer to reach these aims? What are the commonalities and differences between cloud providers such as Microsoft Azure or Google’s GCP? The latter helps architects to understand underlying principles rather than just product features.
The High-Level Network Design for Clouds
Four layers structure the cloud network security (Figure 1), with the second-highest being the most intuitive to understand. This second-highest layer corresponds to classic, simple on-prem networks. An IP range constitutes a network or network zone and gets a name and identifier. It is a moment of creation: let there be a network with the IP range 10.0.0.0 to 10.15.255.255 and call it “production environment headquarters.” In general, network architects should choose addresses from the private IP range, i.e., from 10.0.0.0 to 10.255.255.255, 172.16.0.0 to 172.31.255.255, or 192.168.0.0 to 192.168.255.255.
Figure 1: Core Cloud Network Security Layers for Organizing VM Workloads
Zoning concepts typically reflect one or more of the following dimensions to structure the network landscape and workloads:
Geographical locations: Germany, Switzerland, Singapore, and China – or New York, Boston, San Francisco
Stages, for example, production, preproduction, test, and development
Business lines, e.g., investment banking, retail banking, corporate banking, private banking, or wealth management
Data sensitivity classes such as secret, confidential, internal, or public
IT departments subdivide network zones into subnets, each taking over a subset of the zone’s IP range. A zone with IP range 10.0.0.0 to 10.15.255.255, for example, cloud have two subnets: 10.0.0.0 to 10.0.255.255 and 10.4.0.0 to 10.4.63.255. Subnets allow for finer granular structuring.
Zoning is a complex task – and that is why cloud security architects have to support the design process. Should all VMs of an application reside in one subnet – or all VMs belonging to the same application or solution cluster? Should frontend and backend components reside in one subnet, or should they be in entirely different zones? Security architecture is one (important) stakeholder. Network architecture and business and enterprise architecture have a say as well.
Implementing High-Level Zoning Concepts in Azure
In Azure, VNets and Subnets are the features for implementing zones and subnets. A VNet’s IP range is coherent. IP addresses within a VNet are unique, though different VNets can have overlapping IP addresses. Within VNet A with all its subnets, there can be only one VM with IP 10.10.10.10. However, if an IT department has two VNets Z1 and Z2, both can contain one VM with IP 10.10.10.10. Furthermore, all resources of a VNet, such as VMs, reside in one region.
A fundamental security aspect is the connectivity between VNets and Subnets. Which VMs can talk with each other by default, which ones not, and which kind of shielding can engineers implement? Azure isolates VNets with their subnets and VMs from each other. Without explicit configuration, a VM in one VNet cannot connect to a VM in a different VNet. In contrast, VMs within a VNet can contact each other by default, even if residing in different Subnets. So, placing VMs in two subnets of the same VNet does not provide any extra level of security without additional (fine-granular level) measures we discuss later.
Implementing High-Level Zoning Concepts in GCP
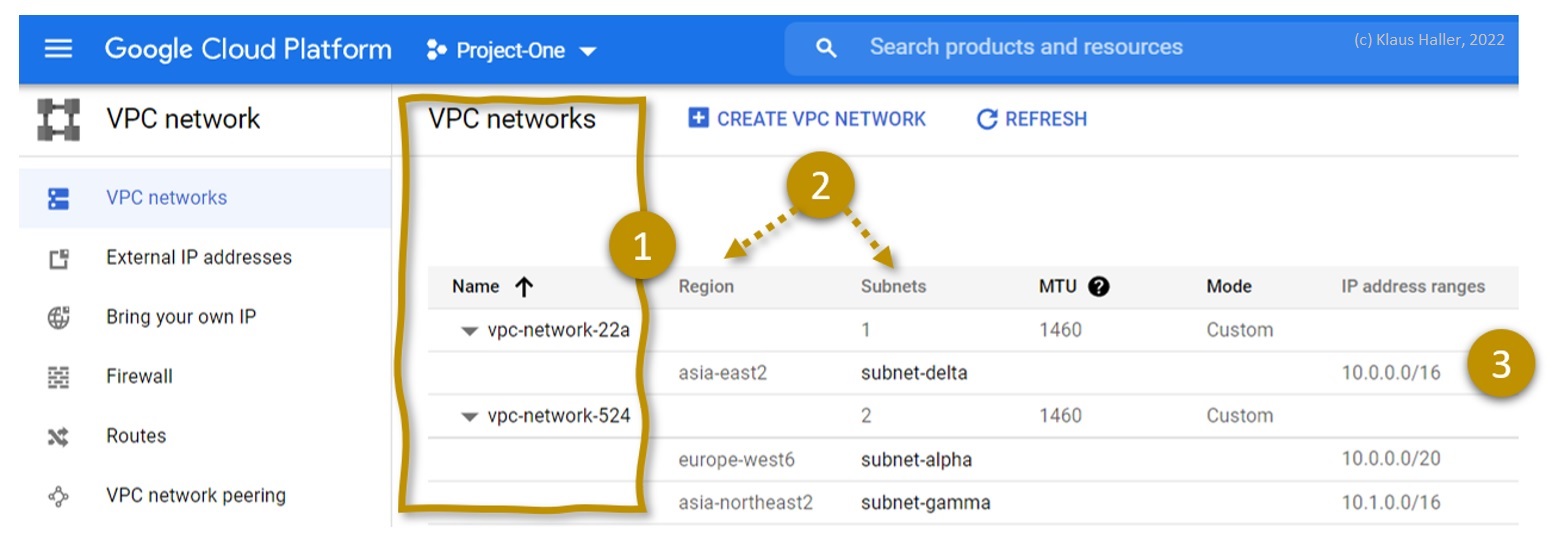
VPC Networks and Subnets are GCP’s corresponding concepts for structuring a network and its IP range. VMs placed in a VPC Network, whether in the same or different GCP Subnets, can reach every other VM within the VPC. GCP allows VPCs to have overlapping IP ranges, as Figure 2 illustrates. In the example, there are VPC Networks with the IP address ranges 10.0.0.0/16 and one with 10.0.0.0/20, which obviously overlap.
Figure 2: VPC Network Overview (1), Subnets belonging to the VPCs and their region (2) plus the associated IP ranges (3)
A GCP Subnet is a feature preventing chaos in large VPC Networks. A Subnet takes over parts of the IP range of the VPC Network to which it belongs. All IPs are unique within a Subnet, implying that Subnet IP ranges do not overlap. In GCP, Subnets also have a geographical aspect. Resources within a GCP Subnet reside in one geographic GCP region.
The Management Layers
The need for a sophisticated management layer for organizing hundreds or more VNets or VPC Networks is evident when looking at the companies and customers the cloud vendors target. They do not want (only) small companies or startups paying for 5 or 10 VMs. They want the big fishes as well: corporations listed in the Swiss Market Index, the Eurostoxx 50, etc. These companies need thousands or ten-thousands of VMs. Two layers – zones such as VNets or VPCs plus Subnets – are insufficient for large clouds. Thus, the cloud providers introduced additional management layers on top.
When trying out the clouds the first time, many get the impression that accounts are the highest ordering principle, typically represented by an email address and an additional name or identifier. But cloud providers offer features for combining accounts to GPC Organizations in the Google world and Azure Management Groups for Microsoft. They help for governance and billing purposes or identities. These features help companies for which the move to the cloud was a decentral (chaotic) grass-root movement – or when company networks and cloud infrastructures evolve over the years due to mergers and acquisitions.
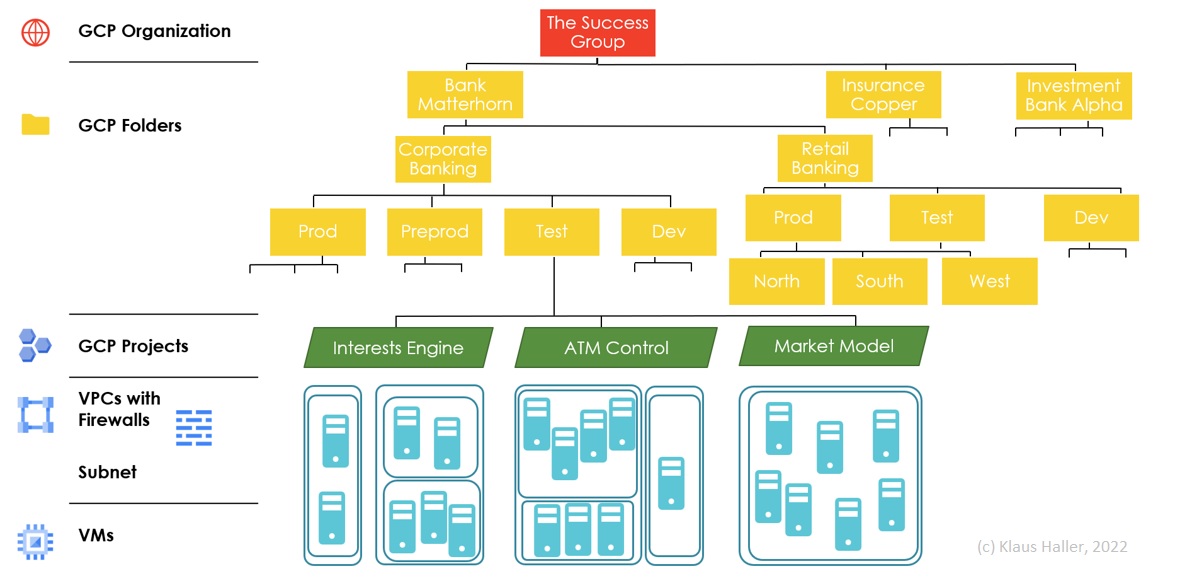
Below an Azure Subscription, aka an account, Microsoft provides the concept of Resource Groups, into which all VMs, VNets, and all other components are placed. Google has the concept of GCP Projects, which corresponds to the Azure Resource Groups. But there is one big difference: Google’s idea of GCP Folders, a tree-like flexible structure with multiple layers and nesting. GCP folders help in modeling and structuring workloads based on various dimensions such as business units, geographic regions, or stages with ease (Figure 3). In contrast, Azure has a rigid 3-levels model: organization, subscription, resource group.
Figure 3: A Closer Look on GCP’s Network Security Layers
The management layers typically provide options to enforce and monitor configurations (“policies”). However, here we focus on directly relevant network security configuration options. In this context, GCP has one related feature: Hierarchical Firewall Policies. GCP allows associating organizations and folders with such policies, which enforce specific firewall rules for all folders and VMs hierarchically lower (or to delegate decisions to lower levels) or restricting the applicability of rules to specific VMs by specifying target networks or service accounts.
Fine-Granular Access Control for Azure
Microsoft and Google follow different philosophies regarding fine-granular access control (and firewalls) within a VNet or VPC Network. Azure provides more – and more rigid – concepts making it essential for engineers to understand the interplay. GCP has fewer, though partially more general or flexible features.
The Azure World
Azure enables architects to secure networks with three concepts: network security groups, application security groups, and firewalls.
A network security group (NSG) is a firewall attached to Azure Subnets or individual VMs (specifically: a VM’s network interface), enabling engineers to control connectivity even within Azure Subnets. An NSG defines which IP addresses outside the Azure Subnet can reach which inside IP address – and vice versa. The rules can apply to individual IPs, groups of IPs, or the complete Subnet. If VMs serve different purposes – frontend, backend, or database servers – NSGs allow configuring their exposure to other subnets or the global internet differently, based on exact necessities and the risk appetite.
Application Security Group (ASG) are a refinement of NSGs and overcome their biggest downside: IP-based rules. IP addresses might change and/or if the number of frontend servers handling customer requests increases, all relevant rules in the NSG rule sets require a modification.
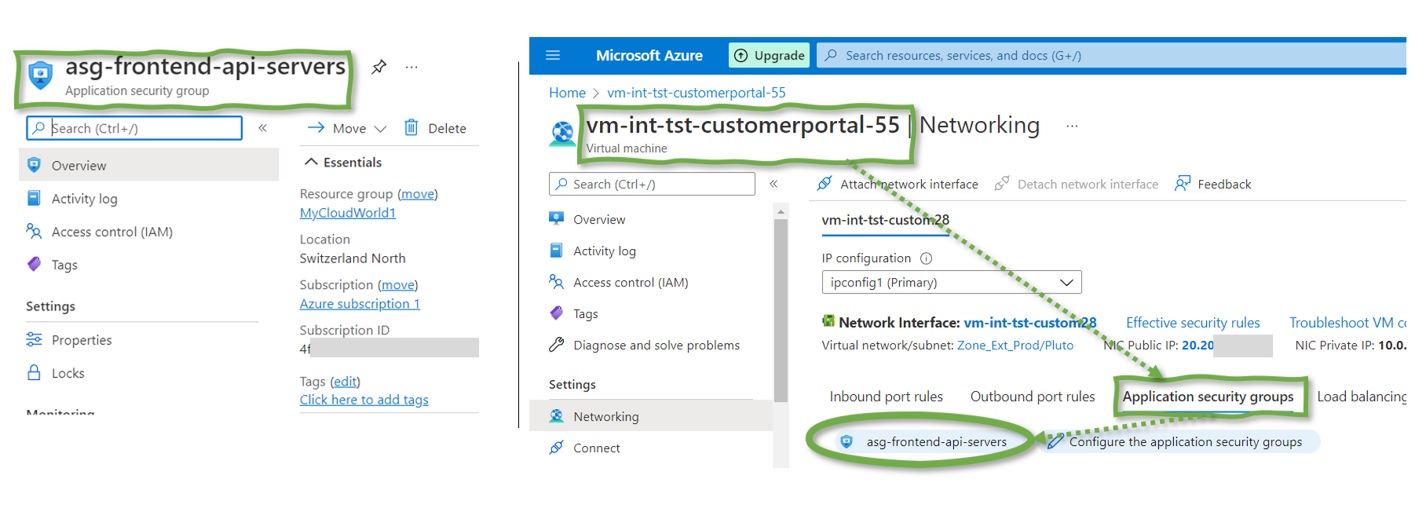
An ASG is a set of VMs with a dedicated tag. They are not (!) Identified based on an IP. Instead of opening the HTTPS port to 10.5.10.26 in a pure NSG setup, ASGs allow opening the HTPPS port for all VMs of the subnet belonging to the ASG “asg-frontend-vms”. The ASG might contain a VM with the IP 10.5.10.26, but any other VM within the subnet would be governed by the same rules as soon, and as long the VM is part of the ASG.
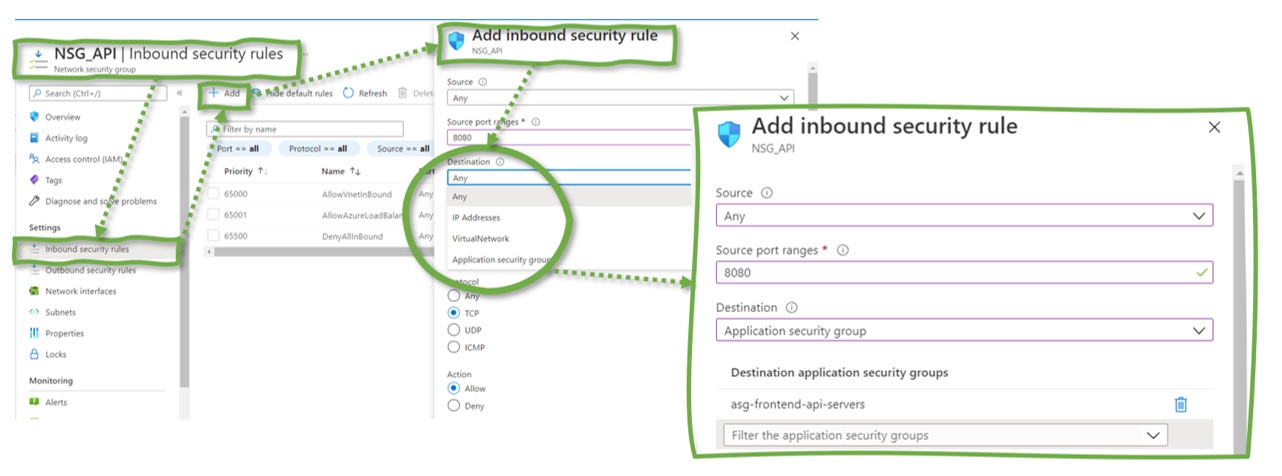
Figure 4 provides an example of an ASG – “asg-frontend-api-servers” – on the left. The sample VM on the right belongs to precisely one ASG: “asg-frontend-api-servers”.
Figure 4: An Application Security Group (ASG) example (left) and how to associate a VM with the ASG.in the Azure Portal
An ASG impacts the VMs associated with it once the ASG becomes part of an NSG. Suppose an NSG allows HTTPS traffic to a VM handling incoming API requests. Then, rather than explicitly listing IPs in the NSG (and updating them when starting or stopping VMs), the engineers create an ASG and add the relevant VMs to this ASG.
Figure 5: Integrating an ASG in an NSG rule.
In addition to VNets, Subnets, Network Security Groups, and Application Security Groups, Azure also allows configuring a dedicated security service, Azure Firewall. Such a firewall helps block unwanted traffic. It is a component typically placed at the perimeter between company VNets and the global internet. In contrast, VNets, Subnets, NSGs, and ASGs help control the company-internal network traffic.
The various components and features might be overwhelming when looked at the first time – and seem to be overlapping. That’s one way to see it. The other way to look at all these features is that managers and architects can achieve the same goal with overlapping features – and thus share responsibilities between teams more efficiently. A high level of network security when going live is necessary, but it is not enough. IT departments have to manage and maintain all network components to stay on the same security level in the years to come. More sophisticated and partially overlapping features make the work distribution more manageable.
Fine-Granular Access Control for GCP
NSGs on the Subnets and the VMs level together with ASGs – Azure provides various options for fine-granular connectivity configuration. In contrast, GCP provides firewalls (only) on the VPC level. Rules applying only to one VM are part of the VPC firewall rulesets. This minor technical finesse impacts network or firewall processes in IT organizations. Rules on the VPC level favor central firewall management, making it more challenging to delegate (some) firewall rule decisions to individual application teams.
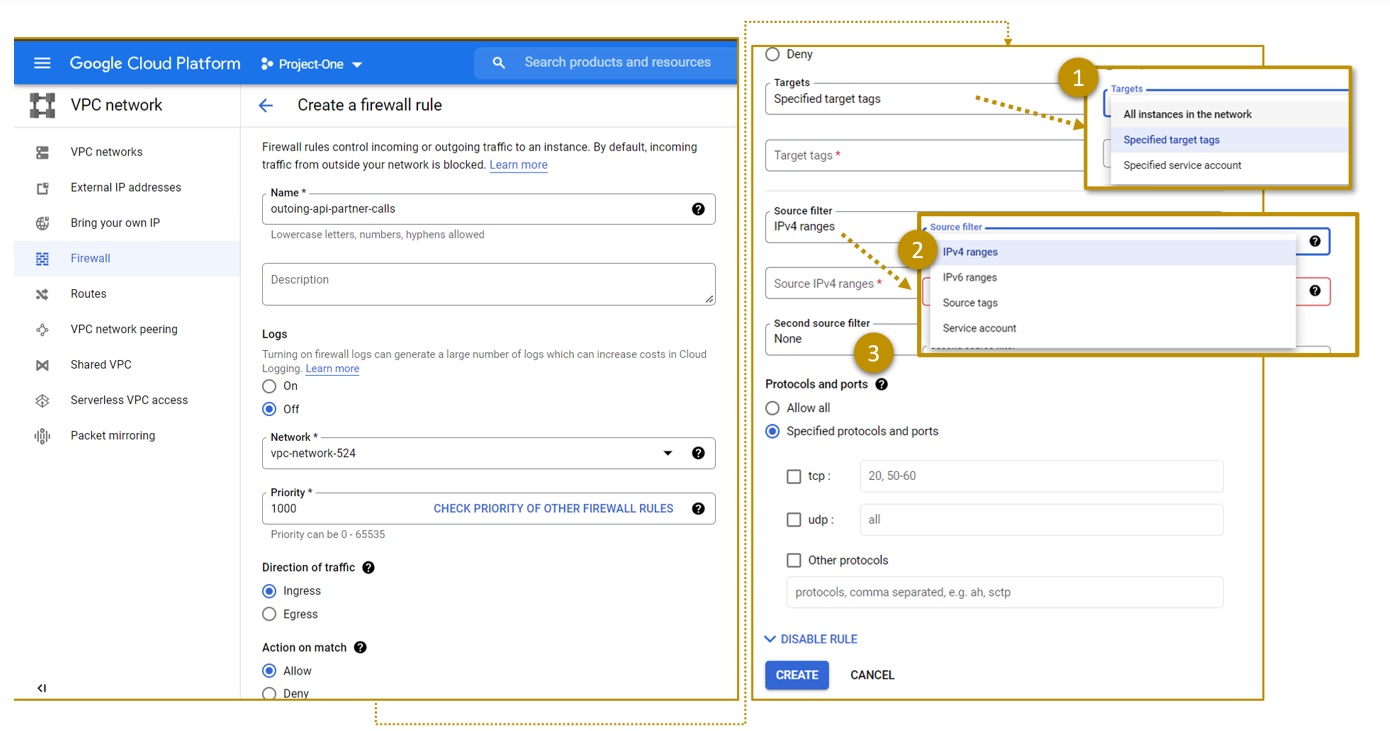
Figure 6 illustrates options for defining VPC Firewall Rules. A rule can apply to all VMs of a VPC Network. It can apply to specifically tagged VMs (like the ASG concept in Azure) or VM with specific service accounts. The latter is a concept not found in Azure. When defining firewall rules, architects can configure the applicability further related to where the network traffic comes from based on IP ranges, source tags, or a service account within the same VPC.
To sum things up: firewall rules and connectivity in GCP and Azure provide different concepts. The result: different setups and organizational approaches. Just one final warning for GCP: The GCP portal presents default rules for opening SSH, ICMP, or even all ingress traffic. These rules simplify the first steps in GCP for newbies – and might result in risky configurations.
Figure 6: Configuring VPC network Firewall Rules in Google’s GCP
Peering
By default, VMs in different VNets and VPC Networks cannot communicate. However, there are solutions for inter-zone communication – and they do not require traffic via the internet: Azure VNet Peering and Google Cloud VPC Network Peering.
Suppose one zone has the IP range 10.0.0.0 to 10.0.255.255 and a second one 10.4.0.0 to 10.4.0.255, VMs, VMs can interact easily. No colliding IP addresses cause issues when determining an actual target VM for traffic. However, why should cloud architects peer zones, thereby allowing communications between VMs placed in two zones to isolate the workloads?
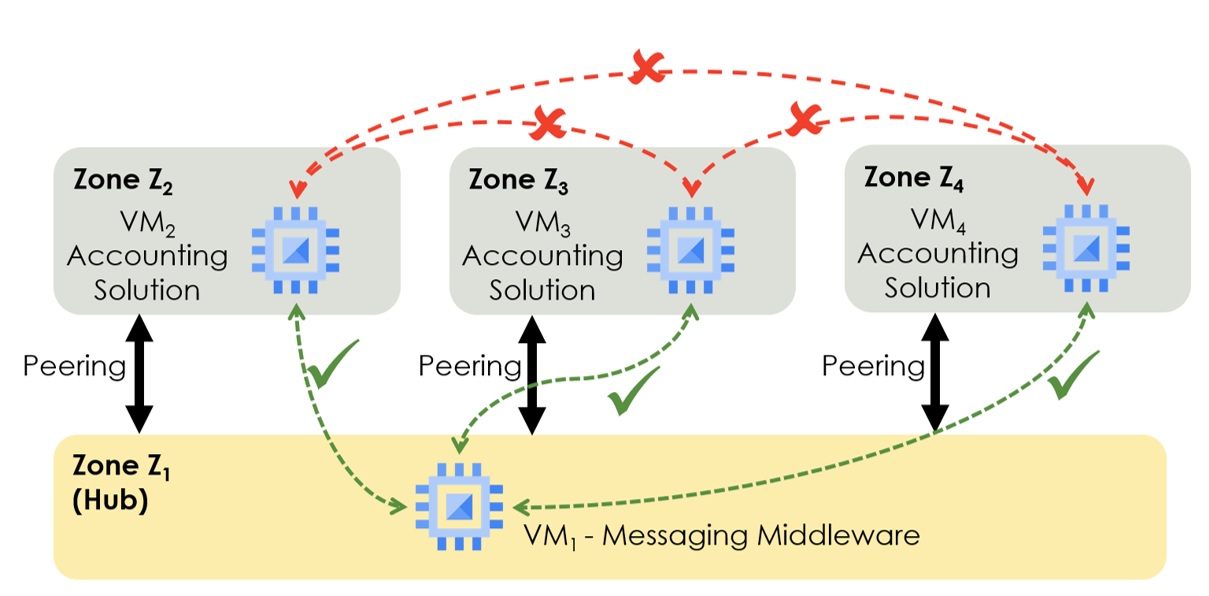
Peering is not beneficial for two-zone networks but for networks with many. GCP, for example, allows peering VPC Networks of the same or different GCP Projects. The VPC Networks can even belong to different GCP Organizations. VMs in peered VPC Networks can communicate with each other if not prevented by firewall rules. The twist is the non-transitive nature of peering. Suppose three VMs – VM1, VM2, and VM3 – are in three different VPC Networks: Z1, Z2, and Z3. Peering Z1 and Z2 plus Z2 and Z3 enables the communication between VM1 and VM2 and between VM2 and VM3, but not between VM1 and VM3. Non-transitive peering is vital when setting up typical hub-and-spoke network designs (Figure 7).
Figure 7: Non-Transitive Peering in GCP – Foundation for Hub-and-Spoke Network Designs
VNet Peering in Azure comes with different features and two main configuration options:
Enabling inbound and/or outbound traffic separately – not just allowing or disabling bidirectional traffic as in GCP
Restricting or approving traffic not originating in the peered VNet, also a feature not available in GCP
Peering is a simple yet powerful concept. It helps enable and control company-internal network communications, especially for setting up zones hosting communication middleware or management components.
Connecting VMs and the Internet
Public IPs for VMs are evil; this is the first message a security architect should hammer into all engineers’ minds. Vulnerabilities on the VM or application layers or simple misconfigurations are potential entry doors for attackers. However, locking up all VMs is also not possible. Admins cannot plugin keyboards to VMs to administer them. They come via the network as well.
The solution? Intermediate components or services that forward only parts of the network traffic (e.g., only TCP while blocking UDP traffic) and potentially even inspect the traffic. In particular, the following components and services are relevant:
Network Address Translation (NAT) Services such as the GCP Cloud NAT or Azure Virtual Network NAT. They allow VMs without public IPs to invoke services on the internet without exposing the VMs to external attackers.
Load Balancers such as the Microsoft Azure Load Balancer or Google’s Cloud Load Balancer. Their primary purpose is to distribute high loads to multiple backend VMs, hiding this fact for the invoking applications. At the same time, a load balancer reduces the attack surface, first by preventing direct access to VMs and, second, by limiting the traffic that gets through, e.g., to the HTTP(S) protocol.
Web Application Firewalls restrict even the content of http(s) requests, preventing, e.g., attacks with malformed invocations.
Azure Bastion allows admins to connect to and manage VMs without publicly exposing a VM with an IP. It works as follows: administrators connect first to the Azure portal. From there, the bastion host provides access to the VMs. A bastion host is a hardened server, making it less likely that (unneeded) components potentially have security issues.
These services are worth more profound analysis. Plus, for some cases, 3rd party solutions are an option, not only the ones from the cloud vendors. But all this is another long story, as is protecting VMs and their workloads against malware and other attacks.
To conclude, Microsoft Azure and Google’s GCP provide similar yet different features for creating and securing networks. Engineers aiming at getting applications to run on VMs benefit from their similarity. In contrast, security architects have a different perspective. They do not want to open up network connections. They must close the obvious and hidden wholes in the network design. For them, it is essential to understand all these little features and details where GCP and Azure – or any other public cloud – differ. It is less searching for easter eggs on a sunny day in spring. It is more isolating and avoiding mines in challenging terrain or stormy sea.
“Check whether all needed services are active!” It was a ubiquitous warning at the beginning of all hands-on labs when I took my first Google Cloud Platform (GCP) tutorials. I could not understand Google’s philosophy. Why would you disable a service? Why does Google not activate them by default and keep them on all the time?
Today, about two years later, I am a big fan of this great feature. It eases my work as a cloud security architect. IT departments benefit from lesser costs and less friction between engineering and security. Plus, the feature helps to protect Platform-as-a-Service (PaaS)-heavy workloads.
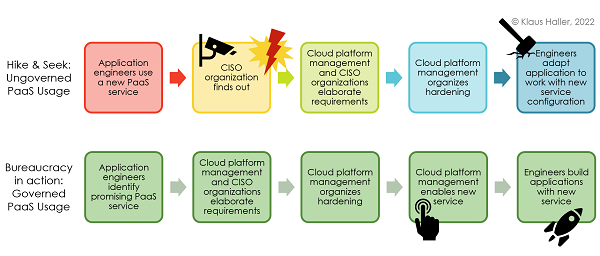
Firewalls keep many attackers away in the old world of servers and virtual machines. In a PaaS world, services are directly exposed internally or to the internet, making inadequate authentication and authorization mechanisms and incomplete configurations a considerable risk. Thus, hardening PaaS services is a necessity. If left to application engineers, some might forget about the hardening or projects under pressure delay the hardening to a later point in the future – and it remains a future task to eternity and beyond. Here, the option to disable PaaS services makes a difference. Figure 1 compares a hide-and-seek and a governance-based working model.
The upper process illustrates what is a matter of time in a larger organization. Application teams use a new, innovative PaaS service without proper hardening. The CISO organization finds out and is furious. Next, they analyze together with the cloud platform management team which configurations are appropriate and necessary for hardening the service. Typically, the hardening bases upon a CIS benchmark or cloud-vendor best practices. Next, the platform management organizes the hardening – and the engineering team (hopefully) does not have to make too many modifications to make their code work with the hardened service.
Figure 1: Hardening approaches with and without security governance
The corporate culture and employee motivation do not benefit from CISOs-turned-cops working style always looking for guilty engineers. Reworking code to work with hardened services causes extra costs, especially when more extensive architectural adjustments are necessary. Plus, there is an increased risk for security incidents till the completion of the hardening. Thus, a more bureaucratic process (Figure 1, lower process) that seems to slow innovation and agility is often the better choice.
When an engineer wants to use a new service, he informs the cloud platform management. The latter elaborates the hardening requirements with the CISO organization and ensures their implementation. Afterward, the cloud platform management makes the newly hardened PaaS service available for the engineers, who integrate it into their solutions.
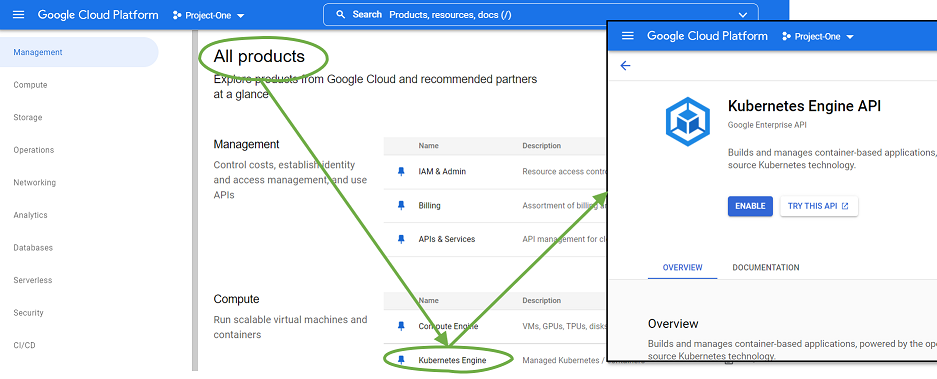
To enable a new PaaS service in the Google Cloud Platform, the cloud platform management changes to the “all products” overview in the GCP console, selects the service it wants to activate, and presses “Enable” (Figure 2). In Google’s GCP, the activation is just a single click on a button.
Over the holiday, I took my time to read this book about state-sponsored attacks. Quite interesting if you want to model potential attacks on your company and organization. My summary in three parts distilled my learnings from reading the book.
Comparing TLS and OAuth 2.0 sounds like comparing apples and pears for seasoned security experts. Still, it is a great way to illustrate the various facets of authentication in complex, open, and interconnected IT landscapes.